Enhancing Document Interactions - Leveraging the synergy of Google Cloud Platform, Pinecone, and LLM in Natural Language Communication
- English
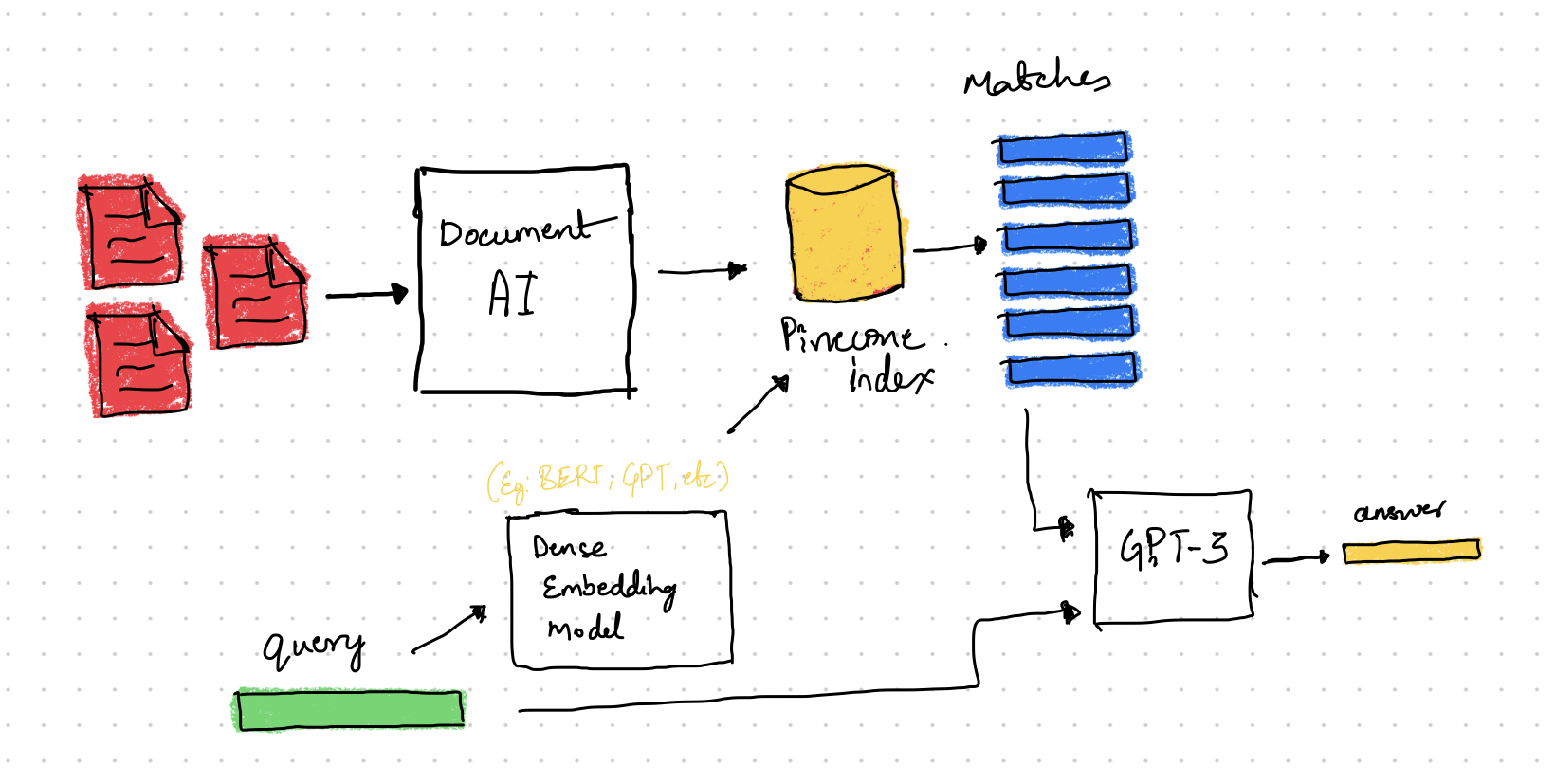 High-level view of system design with Document AI, OpenAI, Pinecone
High-level view of system design with Document AI, OpenAI, Pinecone
In today’s digital era, accessing crucial information from government documents can be overwhelming and time-consuming due to their scanned and non-digitized formats. To address this issue, there is a need for an innovative tool that simplifies navigation, scanning, and digitization of these documents, making them easily readable and searchable. This user-friendly solution will revolutionize the way people interact with government documents, leading to better decision-making, improved public services, and a more informed and engaged citizenry. Developing such a tool is essential for ensuring transparency and accessibility of vital information in the modern world.
To achieve our goal, we will follow a systematic approach consisting of the following steps:
- We will use the powerful Document AI API provided by Google Cloud Platform to convert PDF / Image documents into text format. This step allows us to extract textual content from the documents, making it easier to process and analyze.
- Next, we will employ a Language Model (LLM) to generate embeddings for each text extracted from the documents. These embeddings capture the semantic representation of the text, enabling us to effectively analyze and compare documents based on their content.
- To optimize the retrieval process, we will utilize Pinecone, a robust indexing and similarity search system. By storing the generated embeddings in PineCone, we can quickly search for documents that closely match a user’s query.
- With the acquired knowledge and enhanced search capabilities, our tool will efficiently answer user queries by retrieving the most relevant documents based on their content.
For demonstration of this process, we utilized documents from the Karnataka Resident Data Hub (KRDH) by web scraping.
Demo: Building a powerful question/answering for government documents using Document AI, OpenAI, Pinecone, and Flask
1. Setting Up Google Cloud Platform - Document AI
Document AI is a document understanding platform that converts unstructured data from documents into structured data, making it easier to comprehend, analyze, and utilize. To set up Document AI in your Google Cloud Platform (GCP) Console, follow these steps:
- Enable the Document AI API.
- Create a service account:
- Navigate to the create service account page in the Google Cloud console.
- Choose your project.
- Enter a name in the Service account name field. The Google Cloud console will automatically fill in the Service account ID field based on this name.
- Click Create and continue.
- Grant the Project > Owner role to your service account to provide access to your project.
- Click Continue.
- Click Done to complete the service account creation process. (Do not close your browser window, as you will need it in the next step.)
- Create a service account key:
- In the Google Cloud console, click the email address for the service account you created.
- Click Keys.
- Click Add key, then click Create new key.
- Click Create. A JSON key file will be downloaded to your computer.
- Click Close.
- Set the environment variable GOOGLE_APPLICATION_CREDENTIALS to the path of the JSON file containing your service account key. This variable applies only to your current shell session, so if you open a new session, you will need to set the variable again.
- Install the Client Library:
pip install --upgrade google-cloud-documentai - Create a Processor:
- In the Document AI section of the Google Cloud console, go to the Processors page.
- Click +Create processor.
- Choose the processor type you want to create from the list.
- In the Create processor window, specify a processor name.
- Select your desired region from the list.
- Click Create to generate your processor.
- Take note of the Processor ID and location.
After completing these steps, you are ready to use the Document AI API in your code.
def convert_pdf_images_to_text(file_path: str):
"""
Convert PDF or image file containing text into plain text using Google Document AI.
Args:
file_path (str): The file path of the PDF or image file.
Returns:
str: The extracted plain text from the input file.
"""
extention = file_path.split(".")[-1].strip()
if extention == "pdf":
mime_type = "application/pdf"
elif extention == "png":
mime_type = "image/png"
elif extention == "jpg" or extention == "jpeg":
mime_type = "image/jpeg"
opts = ClientOptions(
api_endpoint=f"{location}-documentai.googleapis.com"
)
client = documentai.DocumentProcessorServiceClient(client_options=opts)
# Add the credentials obtained, Project ID, Location and the Processor ID
name = client.processor_path(
project_id, location, processor_id
)
# Read the file into memory
with open(file_path, "rb") as image:
image_content = image.read()
# Load Binary Data into Document AI RawDocument Object
raw_document = documentai.RawDocument(content=image_content, mime_type=mime_type)
# Configure the process request
request = documentai.ProcessRequest(name=name, raw_document=raw_document)
result_document = client.process_document(request=request).document
return result_document.text
2. Embeddings Generation and Pinecone
In this step, we will use the OpenAI Text Embedding API to generate embeddings that capture the semantic meaning of the extracted text. These embeddings serve as numerical representations of the textual data, allowing us to understand the underlying context and nuances.
After generating the embeddings, we will securely store them in Pinecone, a powerful indexing and similarity search system. By leveraging Pinecone’s efficient storage capabilities, we can effectively organize and index the embeddings for quick and precise retrieval.
With the embeddings stored in Pinecone, our system gains the ability to perform similarity searches. This enables us to find documents that closely match a given query or exhibit similar semantic characteristics.
The following code uses OpenAI’s Text Embedding model to create embeddings for text data. It divides the input text into chunks, generates embeddings for each chunk, and then upserts the embeddings along with associated metadata to a Pinecone search index for efficient searching and retrieval.
def create_embeddings(
text: str, model: str = "text-embedding-ada-002"):
"""
Creates a text embedding using OpenAI's Text Embedding model.
Args:
text (str): The text to embed
model (str, optional): The name of the text embedding model to use.
Defaults to "text-embedding-ada-002".
Returns:
List[float]: The text embedding.
"""
if type(text) == list:
response = openai.Embedding.create(model=model, input=text).data
return [d["embedding"] for d in response]
else:
return [openai.Embedding.create(
model=model, input=[text]).data[0]["embedding"]]∂
def generate_embeddings_upload_to_pinecone(documents: List[Dict[str, Any]]):
"""
Generates text embeddings from the provided documents, then uploads and indexes
them to Pinecone.
Args:
documents (List[Dict[str, Any]]): A list of dictionaries containing
document information.
Each dictionary should include the following keys:
- "Content": The text content of the document.
- "DocumentName": The name of the document.
- "DocumentType": The type/category of the document.
Note:
This function assumes that Pinecone and the associated index have already
been initialized properly. Please make sure to initialize Pinecone first
and set up the index accordingly.
"""
# create chunks
chunks = []
for document in documents:
texts = create_chunks(document["Content"])
chunks.extend(
[
{
"id": str(uuid4()),
"text": texts[i],
"chunk_index": i,
"title": document["DocumentName"],
"type": document["DocumentType"],
}
for i in range(len(texts))
]
)
# initialize Pinecone index, create embeddings, and upsert to Pinecone
index = pinecone.Index("pinecone-index")
for i in tqdm(range(0, len(chunks), 100)):
# find end of batch
i_end = min(len(chunks), i + 100)
batch = chunks[i:i_end]
ids_batch = [x["id"] for x in batch]
texts = [x["text"] for x in batch]
embeds = create_embeddings(text=texts)
# cleanup metadata
meta_batch = [
{
"title": x["title"],
"type": x["type"],
"text": x["text"],
"chunk_index": x["chunk_index"],
}
for x in batch
]
to_upsert = []
for id, embed, meta in list(zip(ids_batch, embeds, meta_batch)):
to_upsert.append(
{
"id": id,
"values": embed,
"metadata": meta,
}
)
# upsert to Pinecone
index.upsert_documents(to_upsert)
For more information on OpenAI’s Text Embedding API, refer to the OpenAI API documentation. For more details on Pinecone, check out the Pinecone documentation.
3. User Query and Communication
Finally, with all the necessary components in place, we can witness the powerful functionality of our tool as it matches user queries with relevant context and provides accurate answers.
When a user submits a query, our system leverages the stored embeddings and advanced search capabilities to identify the most relevant documents based on their semantic similarity to the query. By analyzing the contextual information captured in the embeddings, our tool can retrieve the documents that contain the desired information.
def query_and_combine(
self, query_vector: list, top_k: int = 5, threshold: float = 0.75):
"""Query Pinecone index and combine responses to string
Args:
query_embedding (list): Query embedding
index (str): Pinecone index to query
top_k (int, optional): Number of top results to return. Defaults to 5.
threshold : The similarity threshold. Defaults to 0.75
Returns:
str: Combined responses
"""
responses = index.query(query_vector=query_vector, top_k=top_k, metadata=True)
_responses = []
for sample in responses["matches"]:
if sample["score"] < threshold:
continue
if "text" in sample["metadata"]:
_responses.append(sample["metadata"]["text"])
else:
_responses.append(str(sample["metadata"]))
return " \n --- \n ".join(_responses).replace("\n---\n", " \n --- \n ").strip()
def generate_answer(query: str, language: str = "English"):
"""
Generates an answer to a user's query using the context from Pinecone search results
and OpenAI's chat models.
The function takes the user's query, creates a text embedding from it, performs a
Pinecone query to find relevant context, and then generates an answer using OpenAI's
chat models with the given context.
Returns:
A JSON object containing the generated answer.
Note:
This function assumes that Pinecone and the associated index have already been
initialized properly, and that the OpenAI API is set up correctly. Please
make sure to initialize Pinecone and the OpenAI API first.
"""
query_embed = create_embeddings(text=query)[0]
augmented_query = query_and_combine(
query_embed,
top_k=app.config["top_n"],
threshold=app.config["pinecone_threshold"],
)
## Creating the prompt for model
primer = """You are Q&A bot. A highly intelligent system that answers
user questions based on the context provided by the user above
each question. If the information can not be found in the context
provided by the user you truthfully say "I don't know". Be as concise as possible.
"""
augmented_query = augmented_query if augmented_query != "" else "No context found"
text, usage = openai.ChatCompletion.create(
messages=[
{"role": "system", "content": primer},
{
"role": "user",
"content": f"Context: \n {augmented_query} \n --- \n Question: {query} \n Answer in {language}",
},
],
model=app.config["chat_model"],
temperature=app.config["temperature"],
)
return text
The code consists of two functions.
- query_and_combine() queries a Pinecone index using a query vector, retrieves the top matching responses, and combines them into a single string. It filters the responses based on a similarity threshold and extracts the relevant text or metadata to be included in the combined result.
- generate_answer() generates an answer to a user query. It creates an embedding for the query, performs a combined query on the Pinecone index, and uses the obtained augmented query as context for a chat-based language model. The model generates an answer based on the context and user query, which is then returned as the response. Overall, the code enables querying a Pinecone index, combining responses, and generating answers using a language model based on the given query and context.
As you reach the end of this blog, we hope you have gained valuable insights into the powerful combination of Google Cloud Platform, Pinecone, and Language Models for revolutionizing document interactions. To dive deeper and explore the code behind this innovative solution, visit our GitHub repository. Feel free to clone, modify, and contribute to the project, and don’t hesitate to share your thoughts and experiences. I would also like to thank Tasheer Hussain B for his contributions. Happy coding!
References
Stay in the loop
Get bi-weekly insights on AI agents, SaaS strategy, and the future of software - straight to your inbox.
You're subscribed! Check your inbox soon.
Related Posts
Context Engineering: Why Prompt Engineering Was Never Enough
By 2026, the real job in modern AI systems is not writing a clever prompt. It is deciding what the...
The Filesystem Is the Database: Why Agents Need a New Storage Primitive
RAG pipelines gave agents memory. But the next wave of agentic infrastructure is converging on a different primitive entirely: the...
The SaaSpocalypse: A Survival Guide
Nearly $1 trillion wiped from software stocks in a week. This is not a mass extinction—it's a cleansing fire. Here's...
2026: The Year SaaS Disappeared Into the Conversation
SaaS is shifting from dashboards and clicks to personalized, voice-enabled AI agents that execute outcomes. In 2026, the winning software...