 Source: Menlo Ventures, 2025: The State of Generative AI in the Enterprise [1]
Source: Menlo Ventures, 2025: The State of Generative AI in the Enterprise [1]After reading Jaya Gupta’s post about Context Graphs, I have not been able to stop thinking about it [1]. For me, it did something personal: it gave a name to the architectural pattern I have been circling around in the agentic infrastructure discussions on this blog for the past year.
Gupta’s thesis is simple but profound. The last generation of enterprise software (Salesforce, Workday, SAP) created trillion dollar companies by becoming systems of record. Own the canonical data, own the workflow, own the lock in. The question now is whether those systems survive the shift to agents. Gupta argues they will, but that a new layer will emerge on top of them: a system of record for decisions.
I agree. And I think this is the missing piece that connects everything I have been writing about.
What resonated most with me was Gupta’s articulation of the decision trace. This is the context that currently lives in Slack threads, deal desk conversations, escalation calls, and people’s heads. It is the exception logic that says, “We always give healthcare companies an extra 10% because their procurement cycles are brutal.” It is the precedent from past decisions that says, “We structured a similar deal for Company X last quarter, we should be consistent.”
None of this is captured in our systems of record. The CRM shows the final price, but not who approved the deviation or why. The support ticket says “escalated to Tier 3,” but not the cross system synthesis that led to that decision. As Gupta puts it:
“The reasoning connecting data to action was never treated as data in the first place.”
This is the wall that every enterprise hits when they try to scale agents. The wall is not missing data. It is missing decision traces.
Reading Gupta’s post, I realized that the evolution I have been documenting on this blog (from MCP to Agent Skills to governance) is really a story about building the infrastructure for context graphs. Let me explain.
Phase 1 was about tools. The Model Context Protocol (MCP) gave agents the ability to interact with external systems. It was the plumbing that connected agents to databases, APIs, and the outside world. But we quickly learned that tool access alone is not enough. An agent with a hammer is not a carpenter.
Phase 2 was about skills. Anthropic’s Agent Skills standard gave us a way to codify procedural knowledge, the “how to” guides that teach agents to use tools effectively. Skills are the brain of the agent. They turn tribal knowledge into portable, composable assets. But even skills are not enough. An agent with a hammer and a carpentry manual is still not a master carpenter.
Phase 3 is about context. This is where context graphs come in. A context graph is the accumulated record of every decision, every exception, and every outcome. It answers the question, “What happened last time?” It turns exceptions into precedents and tribal knowledge into institutional knowledge.
| Phase | Primitive | What It Provides | My Analogy |
|---|---|---|---|
| Phase 1 | Tools (MCP) | Capability | The agent has a hammer. |
| Phase 2 | Skills (Agent Skills) | Expertise | The agent has a carpentry manual. |
| Phase 3 | Context (Context Graphs) | Experience | The agent has access to the record of every house it has ever built. |
The governance stack I have been advocating for (agent registries, tool registries, skill registries, policy engines) is the infrastructure that makes context graphs possible. The agent registry provides the identity of the agent making the decision. The tool registry (MCP) provides the capabilities available to that agent. The skill registry provides the expertise that guides the agent’s actions. And the orchestration layer is where the decision trace is captured and persisted.
Without this infrastructure, decision traces are ephemeral. They exist for a moment in the agent’s context window and then disappear. With this infrastructure, every decision becomes a durable artifact that can be audited, learned from, and used as precedent.
Gupta is right that agent first startups have a structural advantage here. They sit in the execution path. They see the full context at decision time. Incumbents, built on current state storage, simply cannot capture this.
But the bigger insight for me is this: we are not just building agents. We are building the decision record of the enterprise. The context graph is not a feature; it is the foundation of a new kind of system of record. The enterprises that win in the agentic era will be those that recognize this and invest in the infrastructure to capture, store, and leverage their decision traces.
We started by giving agents tools. Then we taught them skills. Now, we must give them context. That is the trillion dollar evolution.
References:
[1] Gupta, J. (2025, December 23). AI’s trillion dollar opportunity: Context graphs. X.
--- ## 2025: The Year Agentic AI Got Real (What Comes Next) URL: https://subramanya.ai/2025/12/23/2025-the-year-agentic-ai-got-real-and-what-comes-next/ Date: 2025-12-23 Tags: Agentic AI, Enterprise AI, MCP, Agent Skills, AI Agents, AI Infrastructure, Multi-Agent Systems, AI Governance, Open Standards, 2025 ReviewIf 2024 was the year of AI experimentation, 2025 was the year of industrialization. The speculative boom around generative AI has rapidly matured into the fastest-scaling software category in history, with autonomous agents moving from the lab to the core of enterprise operations. As we close out the year, it’s clear that the agentic AI landscape has been fundamentally reshaped by massive investment, critical standardization, and a clear-eyed focus on solving the hard problems of production readiness.
But this wasn’t just a story of adoption. 2025 was the year the industry confronted the architectural limitations of monolithic agents and began a decisive shift toward a more specialized, scalable, and governable future.
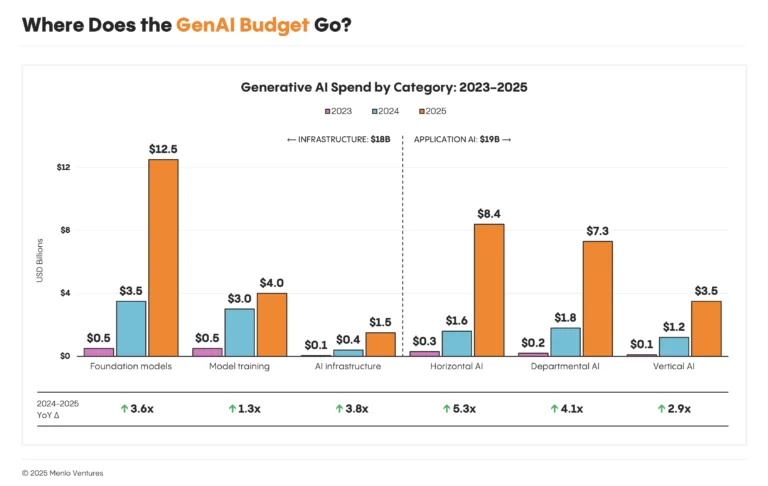
The most telling sign of this shift is the sheer volume of capital deployed. According to a December 2025 report from Menlo Ventures, enterprise spending on generative AI skyrocketed to $37 billion in 2025, a stunning 3.2x increase from the previous year [1]. This surge now accounts for over 6% of the entire global software market.
Crucially, over half of this spending ($19 billion) flowed directly into the application layer, demonstrating a clear enterprise priority for immediate productivity gains over long-term infrastructure bets. This investment is validated by strong adoption metrics, with a recent PwC survey finding that 79% of companies are already adopting AI agents [2].
Source: Menlo Ventures, 2025: The State of Generative AI in the Enterprise [1]
While the spending boom captured headlines, a quieter, more profound revolution was taking place in the infrastructure layer. The primary challenge addressed in 2025 was the interoperability crisis. The early agentic ecosystem was a chaotic landscape of proprietary APIs and fragmented toolsets, making it nearly impossible to build robust, cross-platform applications. This year, two key developments brought order to that chaos.
The Model Context Protocol (MCP), introduced in late 2024, became the de facto standard for agent-to-tool communication. Its first anniversary in November 2025 was marked by a major spec release that introduced critical enterprise features like asynchronous operations, server identity, and a formal extensions framework, directly addressing early complaints about its production readiness [3].
This culminated in the December 9th announcement that Anthropic, along with Block and OpenAI, was donating MCP to the newly formed Agentic AI Foundation (AAIF) under the Linux Foundation [4]. With over 10,000 active public MCP servers and 97 million monthly SDK downloads, MCP’s transition to a neutral, community-driven standard solidifies its role as the foundational protocol for the agentic economy.
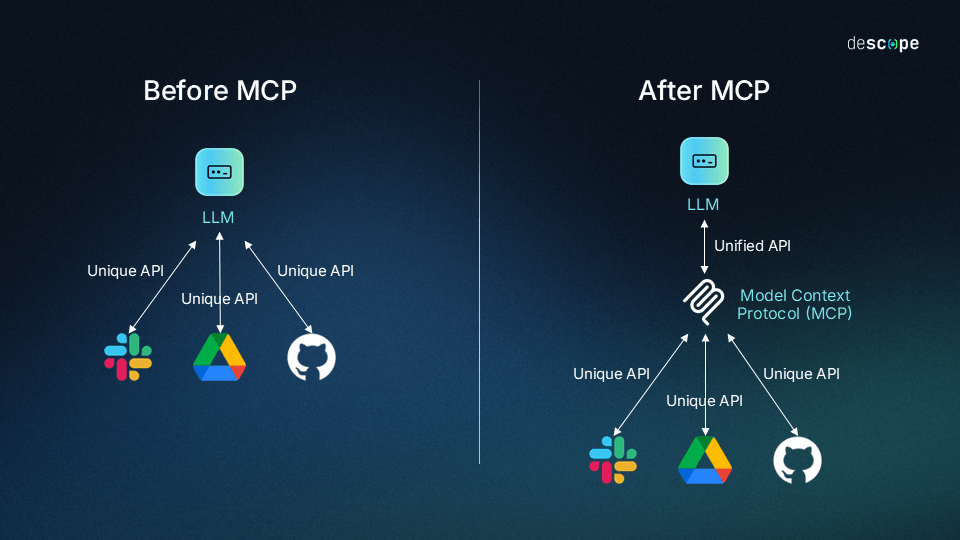 The shift from fragmented, proprietary APIs to a unified, MCP-based approach simplifies agent-tool integration.
The shift from fragmented, proprietary APIs to a unified, MCP-based approach simplifies agent-tool integration.
Following the same playbook, Anthropic made another pivotal move on December 18th, opening up its Agent Skills specification [5]. This provides a standardized, portable way to equip agents with procedural knowledge, moving beyond simple tool-use to more complex, multi-step task execution. By making the specification and SDK available to all, the industry is fostering an ecosystem where skills can be developed, shared, and deployed across any compliant AI platform, preventing vendor lock-in.
These standardization efforts have unlocked the next major architectural shift: the move away from monolithic, general-purpose agents toward collections of specialized skills that function like a human team. No company hires a single “super-employee” to be a marketer, an engineer, and a financial analyst. They hire specialists who excel at their roles and collaborate to achieve a larger goal. The future of enterprise AI is the same.
This “multi-agent” or “skill-based” architecture is not just a theoretical concept. Anthropic’s own research showed that a multi-agent system—with a lead agent coordinating specialized sub-agents—outperformed a single, more powerful agent by over 90% on complex research tasks [6]. The reason is simple: specialization allows for greater accuracy, and parallelism allows for greater scale.
We are already seeing the first wave of companies built on this philosophy. YC-backed Getden.io, for example, provides a platform for non-engineers to build and collaborate with agents that can be composed of various skills and integrations [7]. This approach democratizes agent creation, allowing domain experts—not just developers—to build the specialized “digital employees” they need.
While 2025 solved the problem of connection, 2026 will be about solving the challenges of control and coordination at scale. As enterprises move from deploying dozens of agents to thousands of skills, a new set of problems comes into focus:
Governance at Scale: How do you manage access control, cost, and versioning for thousands of interconnected skills? The risk of “skill sprawl” and shadow AI is immense, demanding a new generation of governance platforms.
Reliability and Predictability: The non-deterministic nature of LLMs remains a major barrier to enterprise trust. For agents to run mission-critical processes, we need robust testing frameworks, better observability tools, and architectural patterns that ensure predictable outcomes.
Multi-Agent Orchestration: As skill-based systems become the norm, the primary challenge shifts from tool-use to agent coordination. How do you manage dependencies, resolve conflicts, and ensure a team of agents can reliably collaborate to complete a complex workflow? This is a frontier problem that will define the next generation of agentic platforms.
Security in a Composable World: A world of interoperable skills creates new attack surfaces. How do you secure the supply chain for third-party skills? How do you prevent a compromised agent from triggering a cascade of failures across a complex workflow? The security model for agentic AI is still in its infancy.
The groundwork laid in 2025 was monumental. It moved us from a world of isolated, experimental bots to the brink of a true agentic economy. But the journey is far from over. The companies that will win in 2026 and beyond will be those that master the art of building, managing, and securing not just agents, but entire workforces of specialized, collaborative skills.
References:
[2] PwC. (2025, May 16). PwC’s AI Agent Survey. PwC.
[6] Anthropic. (2025, June 13). How we built our multi-agent research system. Anthropic Engineering.
[7] Y Combinator. (2025). Den: Cursor for knowledge workers. Y Combinator.
--- ## Agent Skills: The Missing Piece of the Enterprise AI Puzzle URL: https://subramanya.ai/2025/12/18/agent-skills-the-missing-piece-of-the-enterprise-ai-puzzle/ Date: 2025-12-18 Tags: AI Agents, Agent Skills, Enterprise AI, Anthropic, MCP, Agentic AI, AI Governance, Open Standards, AI Infrastructure, Agent ArchitectureThe enterprise AI landscape is at a critical juncture. We have powerful general-purpose models and a growing ecosystem of tools. But we are missing a crucial piece of the puzzle: a standardized, portable way to equip agents with the procedural knowledge and organizational context they need to perform real work. On December 18, 2025, Anthropic took a major step towards solving this problem by releasing Agent Skills as an open standard [1]. This move, following the same playbook that made the Model Context Protocol (MCP) an industry-wide success, is not just another feature release—it is a fundamental shift in how we will build and manage agentic workforces.
General-purpose agents like Claude are incredibly capable, but they lack the specialized expertise required for most enterprise tasks. As Anthropic puts it, “real work requires procedural knowledge and organizational context” [2]. An agent might know what a pull request is, but it doesn’t know your company’s specific code review process. It might understand financial concepts, but it doesn’t know your team’s quarterly reporting workflow. This gap between general intelligence and specialized execution is the primary barrier to scaling agentic AI in the enterprise.
Until now, the solution has been to build fragmented, custom-designed agents for each use case. This creates a landscape of “shadow AI”—siloed, unmanageable, and impossible to govern. What we need is a way to make expertise composable, portable, and discoverable. This is exactly what Agent Skills are designed to do.
At its core, an Agent Skill is a directory containing a SKILL.md file and optional subdirectories for scripts, references, and assets. It is, as Anthropic describes it, “an onboarding guide for a new hire” [2]. The SKILL.md file contains instructions, examples, and best practices that teach an agent how to perform a specific task. The key innovation is progressive disclosure, a three-level system for managing context efficiently:
name and description of each installed skill. This provides just enough information for the agent to know when a skill might be relevant, without flooding its context window.SKILL.md body. This gives the agent the core instructions it needs to perform the task.scripts/, references/, or assets/ directories. This allows skills to contain a virtually unbounded amount of context, loaded only as needed.This architecture is both simple and profound. It allows us to package complex procedural knowledge into a standardized, shareable format. It solves the context window problem by making context dynamic and on-demand. And by making it an open standard, Anthropic is ensuring that this expertise is portable across any compliant agent platform.
| Component | Purpose | Context Usage |
|---|---|---|
Metadata (name, description) |
Skill discovery | Minimal (loaded at startup) |
Instructions (SKILL.md body) |
Core task guidance | On-demand (loaded when skill is activated) |
Resources (scripts/, references/) |
Detailed context and tools | On-demand (loaded as needed) |
It is crucial to understand how Agent Skills relate to the Model Context Protocol (MCP). They are not competing standards; they are complementary layers of the agentic stack. As Simon Willison aptly puts it, “MCP provides the ‘plumbing’ for tool access, while agent skills provide the ‘brain’ or procedural memory for how to use those tools effectively” [3].
For example, MCP might give an agent access to a git tool. An Agent Skill would teach that agent your team’s specific git branching strategy, pull request template, and code review checklist. One provides the capability; the other provides the expertise. You need both to build a truly effective agentic workforce.
By releasing Agent Skills as an open standard, Anthropic is making a strategic bet on interoperability and ecosystem growth. This move has several critical implications for the enterprise:
The Agent Skills specification is, as Simon Willison notes, “deliciously tiny” and “quite heavily under-specified” [3]. This is a feature, not a bug. It provides a flexible foundation that the community can build upon. We can expect to see the specification evolve as it is adopted by more platforms and as best practices emerge.
However, the power of skills—especially their ability to execute code—also introduces new governance challenges. Organizations will need to establish clear processes for auditing, testing, and deploying skills from trusted sources. We will need skill registries to manage the discovery and distribution of skills, and policy engines to control which agents can use which skills in which contexts. These are the next frontiers in agentic infrastructure.
Agent Skills are not just a new feature; they are a new architectural primitive for the agentic era. They provide the missing link between general intelligence and specialized execution. By making expertise composable, portable, and standardized, Agent Skills will unlock the next wave of innovation in enterprise AI. The race is no longer just about building the most powerful models; it is about building the most capable and knowledgeable agentic workforce.
References:
[1] Anthropic. (2025, December 18). Agent Skills. Agent Skills.
[3] Willison, S. (2025, December 19). Agent Skills. Simon Willison’s Weblog.
--- ## From Boom to Build-Out: The State of Enterprise AI in 2026 URL: https://subramanya.ai/2025/12/10/from-boom-to-build-out-the-state-of-enterprise-ai-in-2026/ Date: 2025-12-10 Tags: Enterprise AI, AI Agents, Agentic Workflows, AI Adoption, Platform Strategy, Developer Tools, AI Infrastructure, Generative AI, Enterprise SoftwareThe era of AI experimentation is over. What began as a speculative boom has rapidly industrialized into the fastest-scaling software category in history. According to a new report from Menlo Ventures, enterprise spending on generative AI skyrocketed to $37 billion in 2025, a stunning 3.2x increase from the previous year [3]. This isn’t just hype; it’s a fundamental market shift. AI now commands 6% of the entire global SaaS market—a milestone reached in just three years [3].
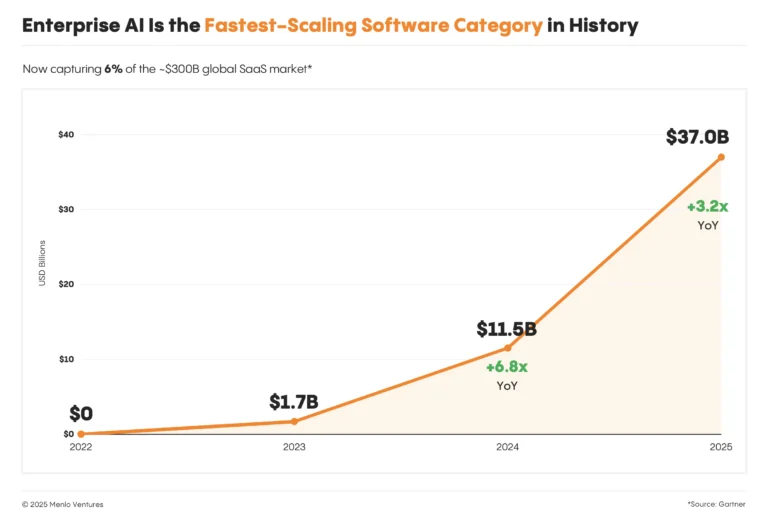
This explosive growth signals a new phase of enterprise adoption. The conversation has moved beyond simple chatbots and one-off tasks to focus on building durable, agentic infrastructure. Reports from OpenAI, Anthropic, and Menlo Ventures all point to the same conclusion: the battleground for competitive advantage has shifted from model performance to platform execution.
So, where is this money going? Over half of all enterprise AI spend $19 billion is flowing directly into the application layer [3]. This indicates a clear preference for immediate productivity gains over long-term, in-house infrastructure projects. The “buy vs. build” debate has decisively tilted towards buying, with 76% of AI use cases now being purchased from vendors, a dramatic reversal from 2024 when the split was nearly even [3].
This trend is fueled by two factors: AI solutions are converting at nearly double the rate of traditional SaaS (47% vs. 25%), and product-led growth (PLG) is driving adoption at 4x the rate of traditional software [3]. Individual employees and teams are adopting AI tools, proving their value, and creating a powerful bottom-up flywheel that short-circuits legacy procurement cycles.
This rapid adoption is not just about doing old tasks faster; it’s about enabling entirely new ways of working. The data shows a clear architectural shift from simple, conversational queries to structured, agentic workflows that are deeply embedded in core business processes.

Anthropic’s 2026 survey reveals that 57% of organizations are already deploying agents for multi-stage processes, with 81% planning to tackle even more complex, cross-functional workflows in the coming year [1]. This transition from single-turn interactions to persistent, multi-step agents is where true business transformation is happening.
OpenAI’s 2025 report highlights a 19x year-to-date increase in the use of structured workflows like Custom GPTs and Projects, with 20% of all enterprise messages now being processed through these repeatable systems [2]. The impact is tangible, with 80% of organizations reporting measurable ROI on their agent investments and workers saving an average of 40-60 minutes per day [1, 2].
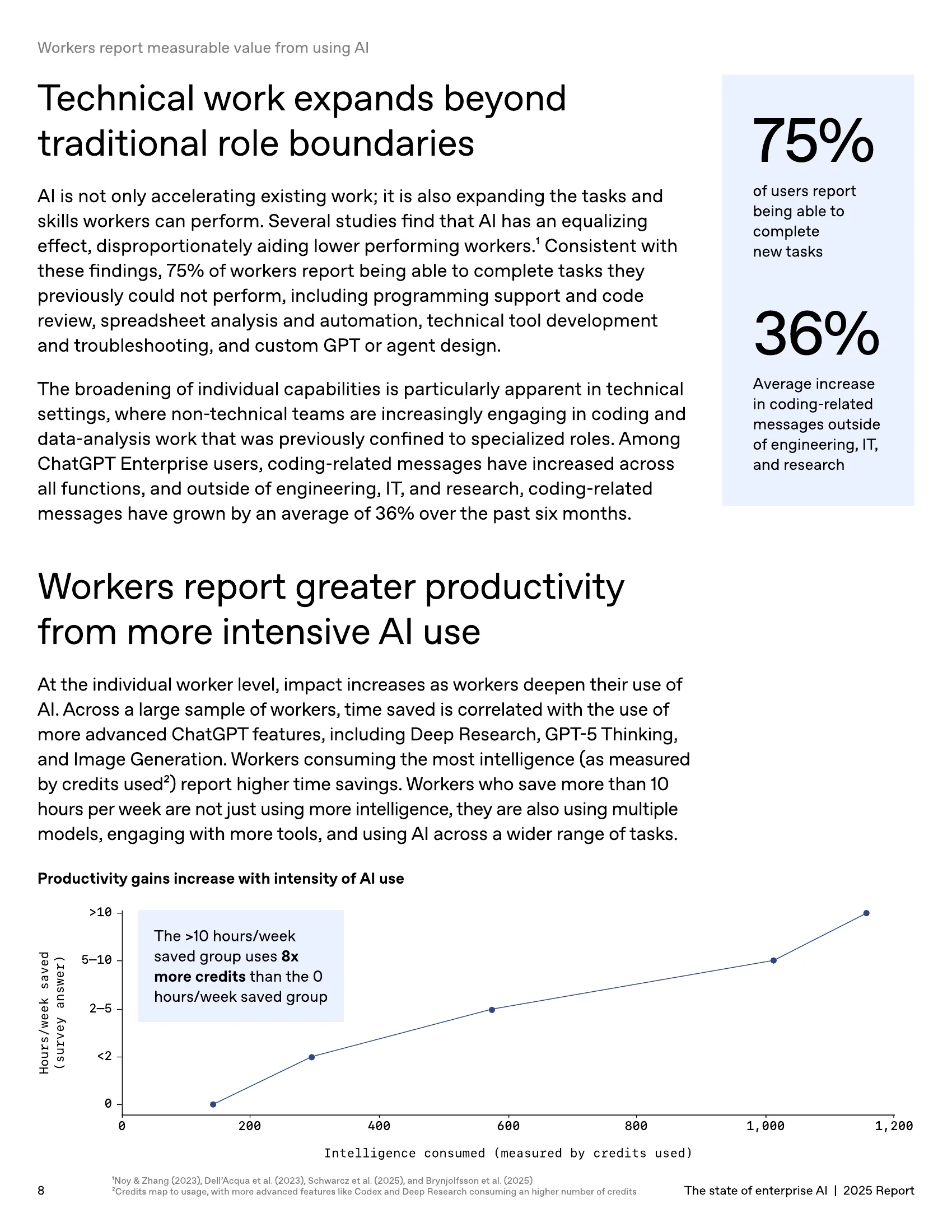
Perhaps most striking is that 75% of workers report being able to complete tasks they previously could not perform, including programming support, spreadsheet analysis, and technical tool development [2]. This democratization of technical capabilities is fundamentally reshaping how work gets done.
Nearly all organizations (90%) now use AI to assist with development, and 86% deploy agents for production code [1]. The adoption is so pervasive that coding-related messages have increased by 36% even among non-technical workers [2].
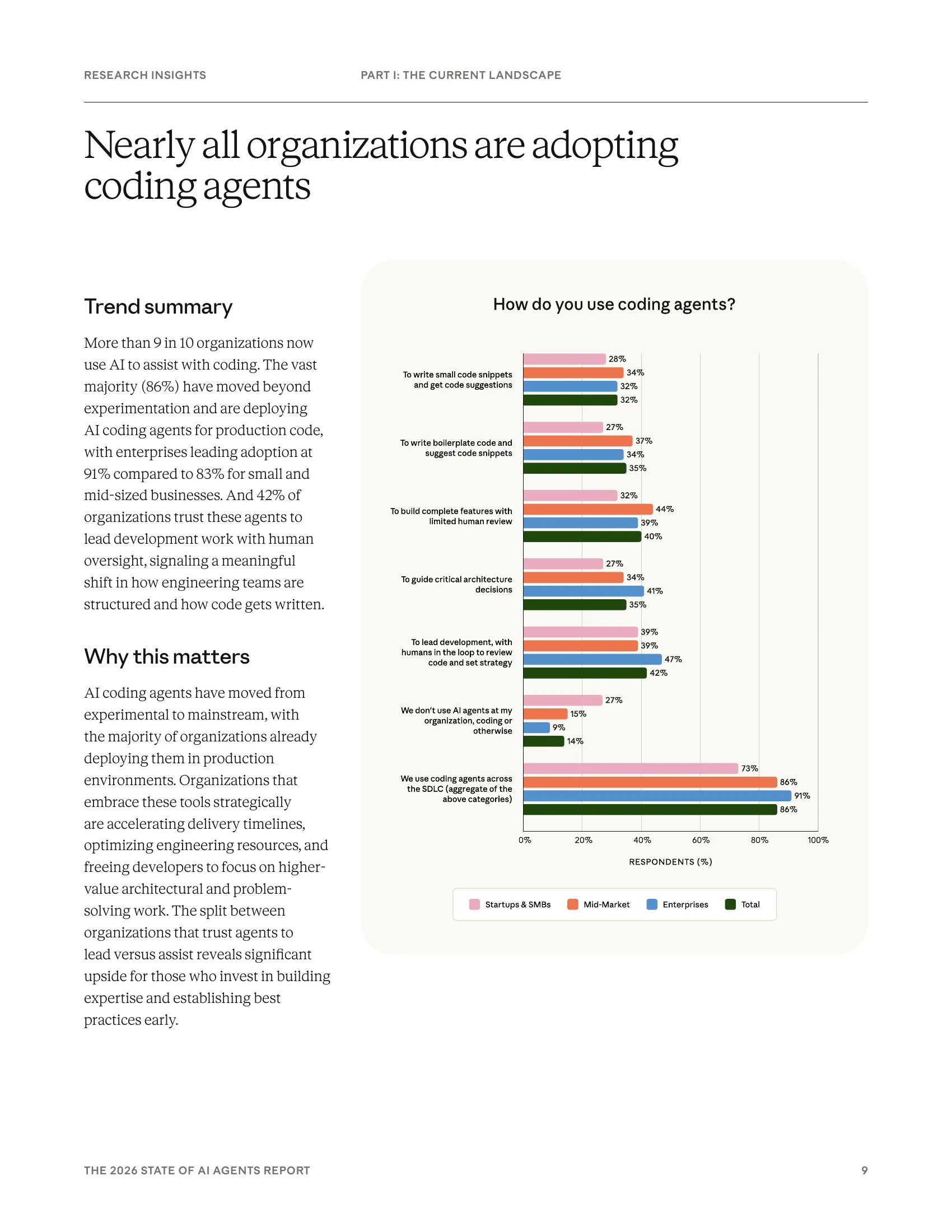
Organizations report time savings across the entire development lifecycle: planning and ideation (58%), code generation (59%), documentation (59%), and code review and testing (59%) [1]. This systematic integration across the full software development lifecycle is accelerating delivery timelines and freeing developers to focus on higher-value architectural and problem-solving work.
As AI becomes an essential, intelligent layer of the enterprise tech stack, the primary barriers to scaling are no longer model capabilities but organizational and architectural readiness. The top challenges cited by leaders are integration with existing systems (46%), data access and quality (42%), and change management (39%) [1]. These are not model problems; they are platform problems.
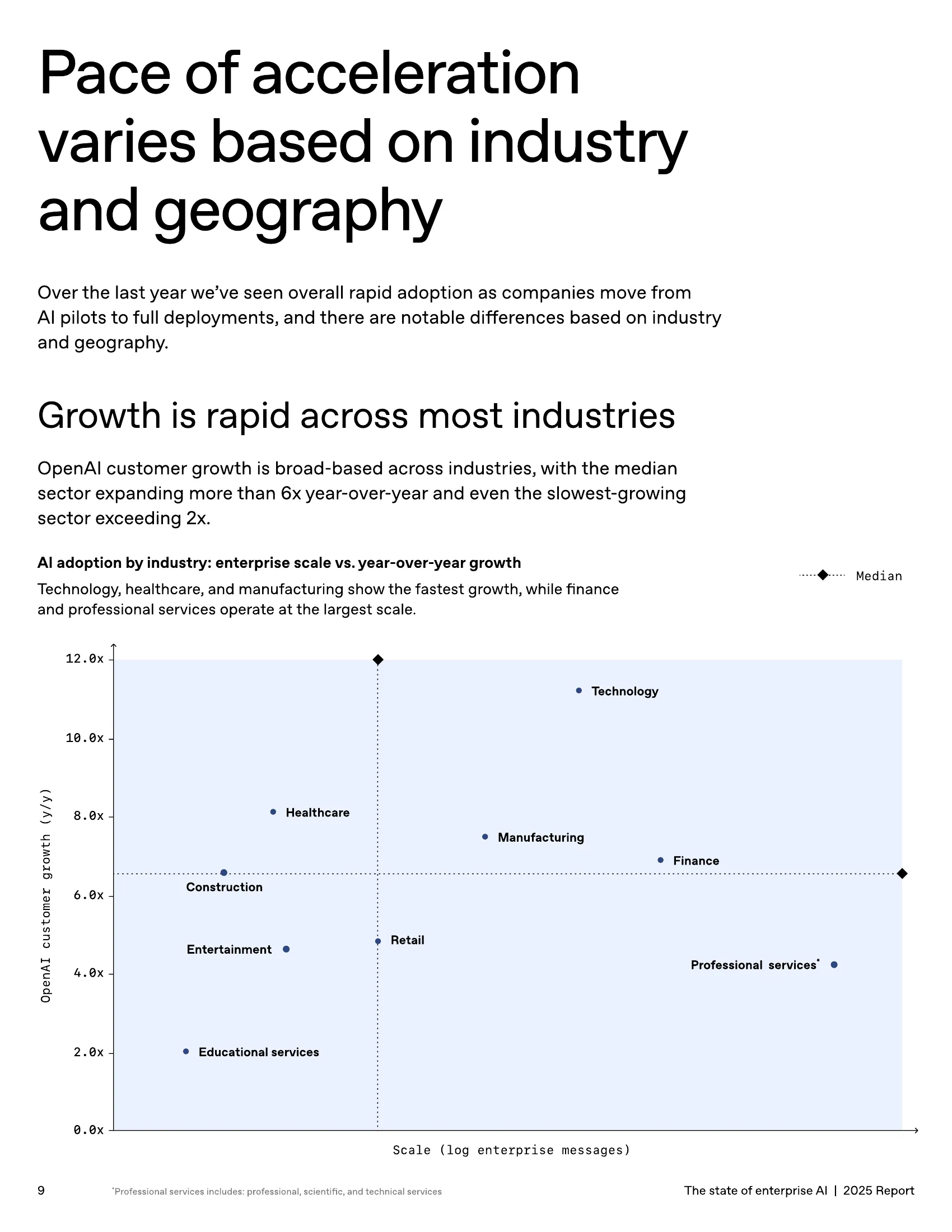
This new reality is creating a widening performance gap. OpenAI’s data shows that “frontier firms” that treat AI as integrated infrastructure see 2x more engagement per seat, and their workers are 6x more active than the median [2]. Technology, healthcare, and manufacturing are seeing the fastest growth (11x, 8x, and 7x respectively), while professional services and finance operate at the largest scale [2].
The state of enterprise AI in 2026 is clear: the gold rush is over, and the era of building the railroads has begun. Success is no longer defined by having the best model, but by having the best platform to deploy, manage, and secure intelligence at scale.
References:
[1] Anthropic. (2025). The 2026 State of AI Agents Report. Anthropic.
[2] OpenAI. (2025). The state of enterprise AI 2025 report. OpenAI.
--- ## The Three-Platform Problem in Enterprise AI URL: https://subramanya.ai/2025/12/07/the-three-platform-problem-in-enterprise-ai/ Date: 2025-12-07 Tags: AI Platform, Enterprise AI, Low-Code, DevOps, Platform Architecture, API-First, Infrastructure, Developer Tools, Platform StrategyEnterprise AI has a platform problem. The tools to build AI-powered applications exist, but they’re scattered across three disconnected ecosystems—each solving part of the puzzle, none providing a complete solution.
This isn’t a “too many choices” problem. It’s an architectural one. Gartner tracks these ecosystems in separate Magic Quadrants because they serve fundamentally different users with different needs. But building production AI applications requires capabilities from all three.
Platforms like Microsoft Power Apps, Mendix, and OutSystems let business users build applications quickly without writing code. They excel at UI, rapid prototyping, and workflow automation.
 Gartner Magic Quadrant for Enterprise Low-Code Application Platforms
Gartner Magic Quadrant for Enterprise Low-Code Application Platforms
What they do well: Speed to prototype, accessibility for non-developers, business process automation.
What they lack: Infrastructure control, enterprise governance at scale, and the flexibility professional developers need.
GitLab, Microsoft Azure DevOps, and Atlassian provide CI/CD pipelines, source control, and deployment infrastructure. They answer the “how do we ship and operate this reliably?” question.
 Gartner Magic Quadrant for DevOps Platforms
Gartner Magic Quadrant for DevOps Platforms
What they do well: Security, governance, testing, deployment automation, operational excellence.
What they lack: They don’t help you build faster—they help you ship what you’ve already built.
Cloud providers (AWS, GCP, Azure) and specialized vendors offer models, MLOps tooling, and inference infrastructure. They provide the intelligence layer.
 Gartner Magic Quadrant for AI Code Assistants
Gartner Magic Quadrant for AI Code Assistants
What they do well: Model access, training infrastructure, inference at scale.
What they lack: An opinion on how you actually build and deploy applications around those models.
When your AI strategy requires stitching together leaders from three separate ecosystems, you pay an integration tax:
Workflow disconnects. A business user prototypes an AI workflow in a low-code tool. A developer rebuilds it from scratch to meet security requirements. The prototype and production system share nothing but a spec document.
Observability gaps. Tracing a user request through a low-code UI, into a DevOps pipeline, through an AI model call, and back is nearly impossible without custom instrumentation.
Governance drift. Security policies enforced in your DevOps platform don’t automatically apply to your low-code environment. Compliance becomes a manual audit.
Your most capable engineers end up writing glue code instead of building products.
The solution isn’t better integrations—it’s platforms built on a different architecture.
Replit offers a useful case study. They’ve grown from $10M to $100M ARR in under six months by building a platform where:
The same infrastructure serves both citizen developers and professionals. A business user building through natural language (“create a customer feedback dashboard”) and a developer writing code are using the same underlying APIs, the same deployment system, the same security model.
AI is native, not bolted on. Their Agent can build, test, and deploy complete applications autonomously—but it’s using the same environment a professional developer would use. No “export to production” step.
Governance applies universally. Database access, API key management, and deployment policies are platform-level concerns. They apply whether you’re prompting an AI agent or writing TypeScript.
This is the “headless-first” pattern that companies like Stripe and Twilio proved out: build the API, make it excellent, then layer interfaces on top. The UI for non-developers and the API for developers are just different clients to the same system.
If you’re evaluating AI platforms, the question isn’t “which low-code tool, which DevOps platform, and which AI vendor?”
The better question: Does this platform unify these concerns, or will we be writing integration code for the next three years?
Look for:
API-first architecture. Can professional developers access everything through APIs? Is the UI built on those same APIs?
Built-in deployment and operations. Does prototyping in the platform give you production-ready infrastructure, or does it give you an export button and a prayer?
Platform-level governance. Are security, compliance, and cost controls configured once and inherited everywhere, or are they per-tool?
The platforms winning in this space aren’t the ones with the longest feature lists. They’re the ones that recognized the three-ecosystem problem and architected around it from day one.
--- ## The Platform Convergence: Why the Future of AI SaaS is Headless-First URL: https://subramanya.ai/2025/12/02/the-platform-convergence-why-the-future-of-ai-saas-is-headless-first/ Date: 2025-12-02 Tags: AI Platform, Agentic AI, Enterprise AI, AI Gateway, Agent Builder, Developer Tools, Infrastructure, Platform Architecture, Headless Architecture, AI SaaSThe AI agent market is experiencing its own big bang—but this rapid expansion is creating fundamental fragmentation. Enterprises deploying agents at scale are caught between two incomplete solutions: Agent Builders and AI Gateways.
Agent Builders democratize creation through no-code interfaces. AI Gateways provide enterprise governance over costs, security, and compliance. Both are critical, but in their current separate forms, they force a false choice: speed or control? The reality is, you need both.
We’ve seen this movie before. The most successful developer platforms—Stripe, Twilio, Shopify—aren’t just slick UIs or robust infrastructure. They are headless-first platforms that masterfully combine both.
Stripe didn’t win payments by offering a payment form. Twilio didn’t win communications by providing a dashboard. They won by providing a powerful, programmable foundation with APIs as the primary interface. Their UIs are built on the same public APIs their customers use. Everything is composable, programmable, and extensible.
| Principle | Benefit |
|---|---|
| API-First Design | Platform’s own UI uses public APIs, ensuring completeness |
| Progressive Complexity | Start with no-code UI, graduate to API without migration |
| Composability | Every capability is a building block for higher-level abstractions |
| Extensibility | Third parties build on the platform, creating ecosystem effects |
This is the blueprint for AI platforms: not just a UI for building agents, nor just a gateway for traffic—but a comprehensive, programmable platform for building, running, and governing AI at every layer.
Agent Builders (Microsoft Copilot Studio, Google Agent Builder) empower non-technical users to create agents in minutes. The problem arises at scale: Who manages API keys? Who tracks costs? Who ensures compliance? This democratization often creates ungoverned “shadow IT”—business units spinning up agents independently, each with its own credentials and error handling. Platform teams discover the proliferation only when something breaks.
AI Gateways (Kong, Apigee) solve the governance problem with centralized security, cost monitoring, and compliance. But a gateway is just plumbing—it doesn’t accelerate creation. Business users wait in IT queues while engineers build what they need. Innovation slows to a crawl.
Integrating both categories creates its own integration tax: two authentication systems, two deployment processes, broken observability across disconnected logs, and policy enforcement gaps where builder retry logic conflicts with gateway rate limits.
The solution is a unified, headless-first platform with four integrated layers:
Layer 1: UI Layer — Intuitive no-code agent builder for business users, built on top of the platform’s own APIs. Natural language definition, visual workflow design, one-click deployment with inherited governance.
Layer 2: Runtime Layer — Enterprise-grade gateway that every agent runs through automatically. Centralized auth (OAuth, OIDC, SAML), real-time policy enforcement, distributed tracing, cost tracking, anomaly detection.
Layer 3: Platform Layer — Comprehensive APIs and SDKs for developers. REST/GraphQL endpoints, language-specific SDKs, agent lifecycle management, webhook system for event-driven architectures.
Layer 4: Ecosystem Layer — Marketplace for discovering and sharing agents, tools, and integrations. Internal registry, reusable components, version control, usage analytics.
The difference between fragmented and unified approaches:
| Capability | Fragmented Tools | Unified Platform |
|---|---|---|
| Agent Creation | Separate builder | Integrated no-code + API/SDK |
| Infrastructure | Separate gateway | Built-in gateway with inherited policies |
| Observability | Disconnected logs | End-to-end unified tracing |
| Policy Management | Manual coordination | Single policy engine |
| Developer Experience | High friction | Single, cohesive API surface |
| Audit & Compliance | Cross-system correlation | Native audit trails |
With a unified platform: business user creates agent in UI → platform applies policies automatically → agent deploys with full observability → platform team monitors centrally → developer extends via API without migration.
Self-Service AI: HR builds a resume screening agent in 20 minutes. It inherits security policies automatically. Cost allocates to HR’s budget. Compliance trail generates without extra work.
AI-Powered Products: Engineers embed agent capabilities into customer-facing apps using platform APIs. Multi-tenant isolation, usage-based billing, and governance come built-in.
Internal Marketplace: Marketing’s “competitive intelligence” agent gets discovered by Sales. One-click deployment. Usage metrics show ROI across the organization.
The debate over agent builder vs. AI gateway is a red herring—a false choice leading to fragmented, expensive solutions. The real question: point solution or true platform?
In payments, Stripe won by unifying developer APIs with merchant tools. In communications, Twilio won by combining carrier control with developer speed. The AI platform market is at the same inflection point.
The future isn’t about stitching tools together; it’s about building on a unified, programmable foundation. The organizations that invest in platform-first infrastructure—rather than cobbling together point solutions—will move faster, govern more effectively, and build more sophisticated agentic systems.
The convergence is coming. The question is whether you’ll be ahead of it or behind it.
--- ## MCP Enterprise Readiness: How the 2025-11-25 Spec Closes the Production Gap URL: https://subramanya.ai/2025/12/01/mcp-enterprise-readiness-how-the-2025-11-25-spec-closes-the-production-gap/ Date: 2025-12-01 Tags: MCP, Enterprise AI, Agentic AI, Security, OAuth, Authentication, Infrastructure, Agent Ops, Governance, Enterprise IntegrationJust over a week ago, the Model Context Protocol celebrated its first anniversary with the release of the 2025-11-25 specification [1]. The announcement was rightly triumphant—MCP has evolved from an experimental open-source project to a foundational standard backed by GitHub, OpenAI, Microsoft, and Block, with thousands of active servers in production [1].
But beneath the celebration lies a more interesting story: this spec release is not just an evolution; it’s a strategic pivot toward enterprise readiness. For the past year, MCP has succeeded as a developer tool—a convenient way to connect AI models to data and capabilities during experimentation. The 2025-11-25 spec is different. It introduces features explicitly designed to solve the operational, security, and governance challenges that prevent organizations from deploying agent-tool ecosystems at enterprise scale.
This article examines three key features from the new spec and analyzes how they close what I call the “production gap”—the distance between experimental agent prototypes and enterprise-grade agentic infrastructure.
Before diving into the technical features, we need to understand the problem they’re solving. Organizations have been experimenting with MCP-powered agents for months, often with impressive results in controlled environments. Yet most of these projects remain trapped in pilot purgatory, unable to progress to production deployments. The barriers are not technical whimsy; they are fundamental operational requirements:
| Requirement | Why It Matters | What’s Been Missing |
|---|---|---|
| Asynchronous Operations | Real-world tasks like report generation, data analysis, and workflow automation can take minutes or hours, not milliseconds. | MCP connections are synchronous. Long-running tasks force clients to hold connections open or build custom polling systems. |
| Enterprise Authentication | Organizations need centralized control over which users, agents, and services can access sensitive tools and data. | The original OAuth flow assumed a consumer app model. It lacked support for machine-to-machine auth and didn’t integrate with enterprise Identity Providers. |
| Extensibility | Different industries and use cases require custom capabilities without fragmenting the core protocol. | There was no formal mechanism to standardize extensions, leading to proprietary, incompatible implementations. |
These aren’t edge cases; they are the table stakes for production systems. The 2025-11-25 spec directly addresses each one.
Perhaps the most transformative addition is the new Tasks primitive [2]. While still marked as experimental, it fundamentally changes how agents interact with MCP servers for long-running operations.
Traditional MCP follows the classic RPC pattern: the client sends a request, the server processes it, and the server returns a response—all within a single connection. This works beautifully for quick operations like reading a database row or checking a weather API. But it breaks down for realistic enterprise workflows:
Organizations have been forced to build custom workarounds: job queues, polling systems, callback webhooks—all non-standard, all increasing complexity and reducing interoperability.
The new Tasks feature introduces a standard “call-now, fetch-later” pattern:
task hint.taskId.working, completed, failed) using standard Task operations.taskId.This is more than syntactic sugar. It provides a uniform abstraction for asynchronous work across the entire MCP ecosystem. An agent framework doesn’t need to know whether it’s calling a data pipeline, a deployment system, or a document processor—the async pattern is the same.
In production environments, this changes everything. An AI assistant orchestrating a complex workflow can:
This is how real autonomous agents operate. The Tasks primitive makes it possible within a standard, interoperable protocol.
The original MCP spec included OAuth 2.0 support, but it was modeled on consumer app patterns (think “Log in with GitHub”). That model doesn’t work for enterprise use cases, where organizations need centralized identity management, audit trails, and policy-based access control. The 2025-11-25 spec introduces two critical updates to close this gap.
The first change is replacing Dynamic Client Registration (DCR) with Client ID Metadata Documents (CIMD) [3]. In the old model, every MCP client had to register with every authorization server it wanted to use—a scalability nightmare in federated enterprise environments.
With CIMD, the client_id is now a URL that the client controls (e.g., https://agents.mycompany.com/sales-assistant). When an authorization server needs information about this client, it fetches a JSON metadata document from that URL. This document includes:
This approach creates a decentralized trust model anchored in DNS and HTTPS. The authorization server doesn’t need a pre-existing relationship with the client; it trusts the metadata published at the URL. For large organizations with dozens of agent applications and multiple MCP providers, this dramatically reduces operational overhead.
The second critical addition is support for the OAuth 2.0 client_credentials flow via the M2M OAuth extension. This enables machine-to-machine authentication—allowing agents and services to authenticate directly with MCP servers without a human user in the loop.
Why does this matter? Consider these enterprise scenarios:
None of these involve an interactive user. They are autonomous services that need persistent, secure credentials to access tools on behalf of the organization. The client_credentials flow is the standard OAuth mechanism for exactly this use case, and its inclusion in MCP makes headless agentic systems viable.
Perhaps the most strategically significant feature for large enterprises is the Cross App Access (XAA) extension. This solves a governance problem that has plagued the consumerization of enterprise AI: uncontrolled tool sprawl.
In the standard OAuth flow, a user grants consent directly to an AI application to access a tool. The enterprise Identity Provider (IdP) sees only that “Alice logged in to the AI app,” not that “Alice’s AI agent is now accessing the payroll system.” This creates a governance black hole.
XAA changes the authorization flow to insert the enterprise IdP as a central policy enforcement point. Now, when an agent attempts to access an MCP server:
This provides centralized visibility and control over the entire agent-tool ecosystem. Security teams can monitor which agents are accessing which tools, set organization-wide policies (e.g., “no agents can access PII without human review”), and audit all delegated access. It eliminates shadow AI and provides the compliance story that regulated industries demand.
Together, these OAuth enhancements transform MCP from a developer convenience into a governed, auditable integration layer. Organizations can:
The third major addition is the introduction of a formal Extensions framework [3]. This is a governance mechanism for the protocol itself, allowing the community to develop new capabilities without fragmenting the ecosystem.
Every successful protocol faces this dilemma: enable innovation fast enough to keep up with evolving use cases, but standardize carefully enough to maintain interoperability. Move too slowly, and the community builds proprietary extensions that fragment the ecosystem. Move too quickly, and the core protocol becomes bloated with niche features that most implementations don’t need.
MCP’s solution is a structured extension process. New capabilities are proposed as Specification Enhancement Proposals (SEPs), which undergo community review and can be adopted incrementally. Extensions are namespaced and clearly marked, so implementations can selectively support them without breaking compatibility.
For enterprises, this is critical. Different industries have unique requirements:
The formal extensions framework allows organizations to develop these capabilities as standard, interoperable extensions rather than proprietary forks. This preserves the core value proposition of MCP—a universal protocol for agent-tool communication—while enabling the customization required for production use.
One more feature deserves mention: Sampling with Tools [3]. This allows MCP servers themselves to act as agentic systems, capable of multi-step reasoning and tool use. A server can now request the client to invoke an LLM on its behalf, enabling server-side agents.
Why is this powerful? It enables compositional agent architectures. A high-level agent can delegate to specialized MCP servers, which themselves use agentic reasoning to fulfill complex requests. For example:
This nested, hierarchical approach is how real autonomous systems will scale. By making it a standard protocol feature rather than a custom implementation, MCP provides the foundation for a rich ecosystem of specialized, composable agents.
The 2025-11-25 MCP specification is not a radical redesign; it’s a targeted set of enhancements that directly address the barriers preventing enterprise adoption. By introducing:
the spec closes the production gap—the distance between experimental prototypes and scalable, secure, enterprise-grade systems.
This is the moment when MCP transitions from a promising developer tool to a foundational piece of enterprise infrastructure. Organizations that have been waiting for “production readiness” signals now have them. The features are there. The governance mechanisms are there. The security model is there.
The next phase of agentic AI will be defined not by flashy demos, but by the quiet, reliable, at-scale operation of autonomous systems integrated deeply into enterprise workflows. The 2025-11-25 MCP spec is the technical foundation that makes this future possible.
For technology leaders evaluating whether to invest in MCP-based infrastructure, the calculus has changed. This is no longer an experimental protocol; it’s a production standard. The organizations that adopt it now, build their agent ecosystems on it, and contribute to its continued evolution will define the next decade of enterprise AI.
References:
[2] Model Context Protocol. (2025, November 25). Tasks. Model Context Protocol Specification.
--- ## The Governance Stack: Operationalizing AI Agent Governance at Enterprise Scale URL: https://subramanya.ai/2025/11/20/the-governance-stack-operationalizing-ai-agent-governance-at-enterprise-scale/ Date: 2025-11-20 Tags: AI, Agents, Agentic AI, Governance, Enterprise AI, Agent Ops, MCP, Security, Infrastructure, Compliance, AI ManagementEnterprise adoption of AI agents has reached a tipping point. According to McKinsey’s 2025 global survey, 88% of organizations now report regular use of AI agents in at least one business function, with 62% actively experimenting with agentic systems [1]. Yet this rapid adoption has created a critical disconnect: while organizations understand the importance of governance, they struggle with the implementation of it. The same survey reveals that 40% of technology executives believe their current governance programs are insufficient for the scale and complexity of their agentic workforce [1, 2].
The problem is not a lack of frameworks. Numerous organizations have published comprehensive governance principles—from Databricks’ AI Governance Framework to the EU AI Act’s regulatory requirements [2]. The problem is that governance has remained largely conceptual, living in policy documents and compliance checklists rather than in the operational infrastructure where agents actually execute.
This article presents the technical foundation required to operationalize governance at scale: the Governance Stack. This is the integrated set of platforms, protocols, and enforcement mechanisms that transform governance from aspiration into automated reality across the entire agentic workforce lifecycle.
Traditional enterprise governance models were designed for static systems and predictable workflows. An application goes through a review process, gets deployed, and then operates within well-defined boundaries. Governance checkpoints are discrete events: code reviews, security scans, compliance audits.
Agentic AI shatters this model. Agents are dynamic, adaptive systems that make autonomous decisions, spawn sub-agents, and interact with constantly evolving toolsets. They don’t follow predetermined paths; they reason, plan, and execute based on context. As one industry analysis puts it, the governance question shifts from “did the code do what we programmed?” to “did the agent make the right decision given the circumstances?” [3].
This creates four fundamental challenges that traditional governance infrastructure cannot address:
| Challenge | Traditional Governance | Agentic Reality |
|---|---|---|
| Decision-Making | Predetermined logic paths, testable and auditable | Context-dependent reasoning, emergent behavior |
| Delegation | Single service boundary, clear ownership | Recursive agent chains, distributed responsibility |
| Policy Enforcement | Deployment-time checks, periodic audits | Real-time enforcement at the moment of action |
| Auditability | Static code and logs | Dynamic decision traces across multiple agents and tools |
The governance gap is the distance between what existing frameworks prescribe and what existing infrastructure can enforce. Closing this gap requires purpose-built technology.
Drawing on the foundational pillars outlined in frameworks like Databricks’ AI Governance model [2], we can define a technical architecture—a Governance Stack—that provides the infrastructure necessary to operationalize these principles. This stack has five integrated layers, each addressing a specific aspect of agent lifecycle management.
Before governance can be enforced, we must know who (or what) is making a request. This requires a robust identity layer specifically designed for autonomous agents, not just human users.
As discussed in previous work on OIDC-A (OpenID Connect for Agents), this layer provides [4]:
This identity foundation is the prerequisite for all subsequent layers. Without it, governance policies have no subject to act upon.
Governance requires visibility. The second layer of the stack is a comprehensive registry system that provides a single source of truth for:
As explored in our previous article on private registries, this layer transforms governance from a manual audit process into an automated, enforceable function of the infrastructure itself [5]. Agents that aren’t registered can’t deploy. Tools that haven’t been vetted can’t be accessed.
The third layer is where governance rules are codified and enforced in real-time. This includes:
Agent Firewalls and MCP Gateways: Acting as intermediaries between agents and their tools, these gateways inspect every request, enforce security policies, and block unauthorized actions before they occur [6]. They provide:
Automated Policy Enforcement: Instead of relying on manual reviews, the policy engine automatically validates agents against organizational standards at every lifecycle stage. For example, an agent cannot be promoted to production without:
This layer is the operational heart of the governance stack. It is where abstract policies become concrete actions that prevent harm in real-time.
Governance is not a one-time gate; it requires continuous oversight. The fourth layer provides real-time visibility into the behavior of the entire agentic workforce:
This layer transforms governance from reactive (responding to incidents after they occur) to proactive (detecting and preventing issues before they cause harm).
The final layer recognizes that not all decisions can or should be fully automated. For high-stakes scenarios, governance requires explicit human oversight:
This is not about replacing human judgment; it’s about augmenting it with the right information at the right time.
The power of the Governance Stack becomes clear when we map it to the complete agent lifecycle. Governance is not a single checkpoint; it is a continuous process embedded at every stage.
| Lifecycle Stage | Governance Stack in Action |
|---|---|
| Planning & Design | Identity layer establishes agent ownership. Policy engine validates business case against organizational risk appetite. |
| Data Preparation | Registries enforce data classification and lineage tracking. Policy engine blocks access to non-compliant datasets. |
| Development & Training | Observability platform tracks experiments and model performance. Registries version all agent configurations. |
| Testing & Validation | Agent firewall tests for adversarial inputs and prompt injections. Policy engine validates against security and ethical standards. |
| Deployment | Gateway enforces real-time authorization for all tool access. Observability platform begins continuous monitoring. |
| Operations | Monitoring platform detects drift and anomalies. Human-in-the-loop mechanisms escalate high-stakes decisions. |
| Retirement | Registries archive agent configurations. Identity layer revokes all permissions. Audit trails are retained for compliance. |
This lifecycle-aware approach ensures that governance is not an afterthought, but an integrated function of how agents are built, deployed, and managed.
Implementing a comprehensive Governance Stack is a significant investment. Organizations rightfully ask: what is the return?
The answer lies in four measurable outcomes:
Risk Mitigation: As demonstrated by the recent AI-orchestrated cyber espionage campaign disrupted by Anthropic [6], uncontrolled agent access to powerful tools is not a theoretical threat. A governance stack with identity attestation, gateways, and real-time policy enforcement would have prevented that attack at multiple layers.
Regulatory Compliance: With regulations like the EU AI Act imposing strict requirements on high-risk AI systems, the ability to demonstrate comprehensive lifecycle governance, auditability, and human oversight is not optional—it’s mandatory [2]. The Governance Stack provides the automated evidence generation required for compliance.
Operational Efficiency: Without centralized registries and monitoring, organizations waste time debugging agent failures, tracking down tool dependencies, and investigating cost overruns. The stack provides the visibility and control to operate an agentic workforce at scale.
Trust and Adoption: The ultimate ROI is internal and external trust. Employees, customers, and regulators need confidence that autonomous agents are operating safely, ethically, and in alignment with organizational values. The Governance Stack makes that confidence possible.
Organizations face a critical decision: build this governance infrastructure in-house or adopt emerging platforms that provide it as a service. Early movers are choosing different paths:
The optimal path depends on organizational maturity, existing infrastructure, and the scale of agentic deployment. However, the underlying message is universal: governance at scale requires dedicated infrastructure.
The era of experimental agentic AI pilots is ending. Organizations are now operationalizing agentic workforces across critical business functions, and the governance gap is the primary barrier to scaling these deployments safely and responsibly.
The Governance Stack is not a constraint on innovation; it is the foundation that makes innovation sustainable. By providing identity, visibility, policy enforcement, continuous monitoring, and human oversight, this technical infrastructure transforms governance from a compliance burden into a strategic enabler.
The organizations that invest in this stack today will be the ones that confidently deploy autonomous agents at enterprise scale tomorrow. They will move faster, operate more safely, and earn the trust of stakeholders who demand accountability in the age of autonomous AI.
For technology leaders navigating this landscape, the path is clear: governance is not a policy problem—it is an engineering challenge. And like all engineering challenges, it requires purpose-built infrastructure to solve. The Governance Stack is that infrastructure.
References:
[1] McKinsey & Company. (2025, November 5). The State of AI in 2025: A global survey. McKinsey.
[2] Databricks. (2025, July 1). Introducing the Databricks AI Governance Framework. Databricks.
[4] Subramanya, N. (2025, April 28). OpenID Connect for Agents (OIDC-A) 1.0 Proposal. subramanya.ai.
[7] TrueFoundry. (2025, September 10). What is AI Agent Registry. TrueFoundry.
--- ## Why Private Registries are the Future of Enterprise Agentic Infrastructure URL: https://subramanya.ai/2025/11/17/why-private-registries-are-the-future-of-enterprise-agentic-infrastructure/ Date: 2025-11-17 Tags: AI, Agents, Agentic AI, MCP, Agent Registry, Enterprise AI, Governance, Security, Infrastructure, Private Registry, AI ManagementThe age of agentic AI is no longer on the horizon; it’s in our datacenters, cloud environments, and business units. A recent PwC report highlights that a staggering 79% of companies are already adopting AI agents in some capacity [1]. As these autonomous systems proliferate, executing tasks and making decisions on behalf of the enterprise, a critical governance gap has emerged. Without a robust management framework, organizations risk a chaotic landscape of “shadow AI,” creating significant security vulnerabilities, compliance nightmares, and operational inefficiencies.
The solution lies in a new class of enterprise software: the Private Agent and MCP Registry. This is not just a catalog, but a command center for agentic infrastructure, providing the visibility, governance, and security necessary to scale AI responsibly. Let’s explore the core pillars of this trend, using the “Agentic Trust” platform as a blueprint for building a better, more secure agentic future.
The first step to managing agentic chaos is to establish a single source of truth. You cannot govern what you cannot see. A private agent registry provides a comprehensive, real-time inventory of every agent operating within the enterprise, whether built in-house or sourced from a third-party vendor.
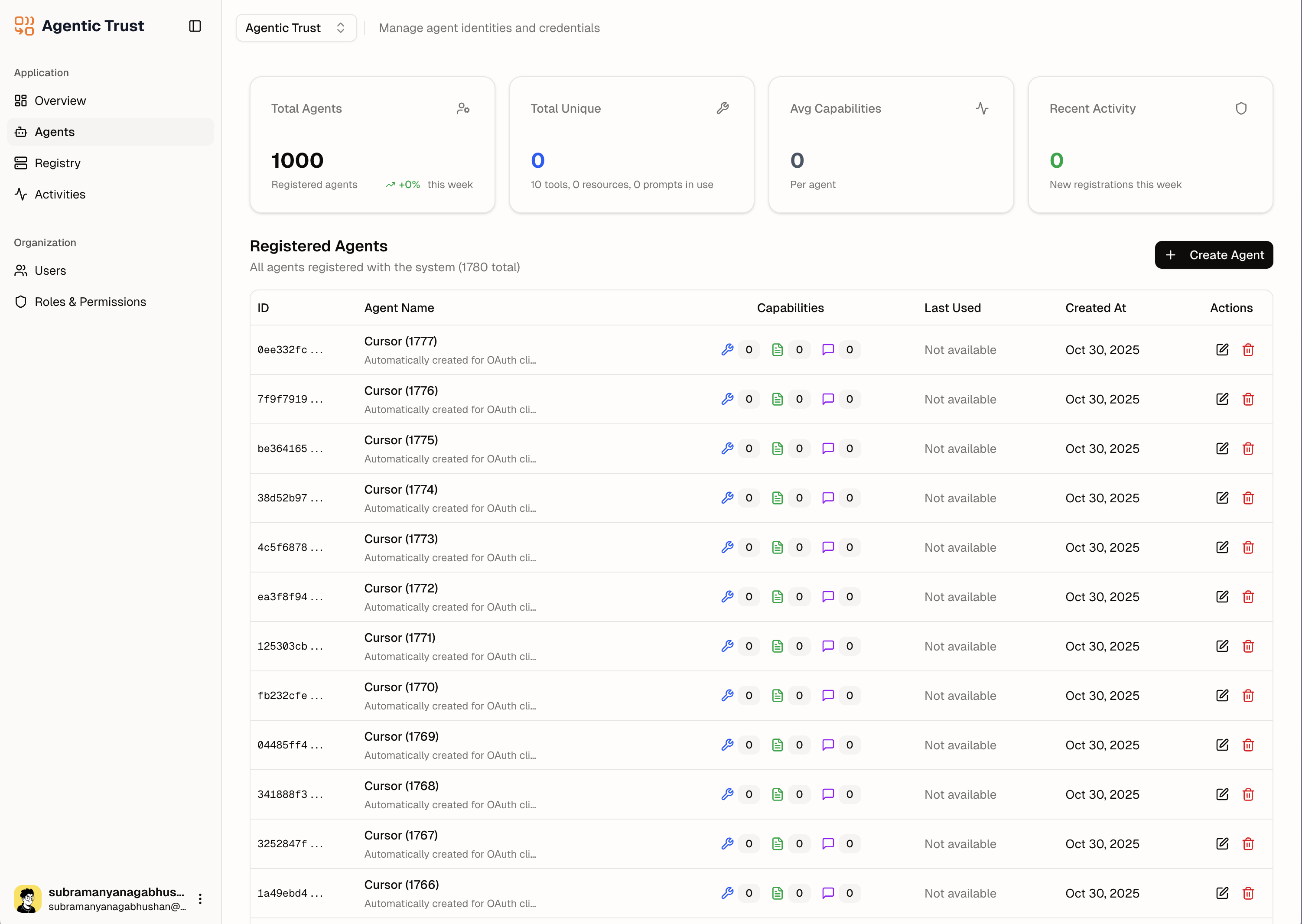 A centralized agent directory, as shown in the Agentic Trust platform, provides a complete inventory for governance and oversight.
A centralized agent directory, as shown in the Agentic Trust platform, provides a complete inventory for governance and oversight.
As the screenshot of the Agentic Trust directory illustrates, this is more than just a list. A mature registry tracks critical metadata for each agent, including:
This centralized view eliminates blind spots and provides the traceability required for compliance and security audits. Organizations can quickly answer critical questions: How many agents do we have? Who owns them? What are they authorized to do?
Autonomous agents are only as powerful as the tools they can access. The Model Context Protocol (MCP) has become a standard for providing agents with these tools, but an uncontrolled proliferation of MCP servers creates another layer of risk. A private registry addresses this by functioning as a curated, internal “app store” or marketplace for MCPs.
 An MCP Registry, like this one from Agentic Trust, allows enterprises to create a governed marketplace of approved tools for their AI agents.
An MCP Registry, like this one from Agentic Trust, allows enterprises to create a governed marketplace of approved tools for their AI agents.
Instead of allowing agents to connect to any public MCP, the enterprise can define a catalog of approved, vetted, and secure tools. As shown in the Agentic Trust MCP Registry, this allows organizations to:
The registry shows connection status for each MCP server, making it immediately visible which integrations are active and which require attention. This operational visibility is critical for maintaining a healthy agentic ecosystem.
A private registry is the enforcement point for enterprise AI policy. It moves governance from a manual, after-the-fact process to an automated, built-in function of the agentic infrastructure. Drawing on best practices from platforms like Collibra and Microsoft Azure’s private registry implementations, this includes [1, 2]:
Mandatory Metadata and Documentation: Before an agent or MCP can be registered, developers must provide essential information such as data classification, business owner, purpose, and criticality. This ensures that every component in the agentic ecosystem is properly documented and understood.
Lifecycle Policy Alignment: The registry can embed automated policy checks at each stage of an agent’s lifecycle. For example, an agent cannot be promoted to production without a completed security review, ethical bias assessment, and approval from the designated business owner. This creates natural checkpoints that enforce organizational standards.
Access Control and Permissions: Using Role-Based Access Control (RBAC), integrated with enterprise identity systems like Entra ID or Okta, the registry defines who can create, manage, and consume agents and their tools. Different teams might have different levels of access based on their role and the sensitivity of the agents they’re working with.
Audit Trails and Compliance: Every action in the registry—agent registration, tool connection, permission changes—is logged and auditable. This creates a complete forensic trail that satisfies regulatory requirements and enables rapid incident response when issues arise.
The value of a private registry becomes clear when we examine the specific problems it solves. Consider these common enterprise scenarios:
Development teams are rapidly adopting AI tools and MCP servers without central oversight. This creates security blind spots, compliance risks, and operational fragmentation across the organization. A private registry provides centralized discovery of approved tools and usage visibility, allowing security teams to monitor what tools are being used and by whom [2].
Organizations in regulated industries (financial services, healthcare, government) need to maintain strict control over data flows and ensure AI tools meet compliance requirements. The registry enables data classification tagging for MCP servers, geographic controls for region-specific availability, comprehensive audit trails, and pre-configured compliance templates [2].
Without visibility into agent and tool usage, organizations face unpredictable costs as autonomous agents make API calls and consume resources. A private registry provides usage analytics, cost allocation by team or project, budget alerts, and the ability to deprecate underutilized or expensive tools [2].
Developers waste time rebuilding integrations that already exist elsewhere in the organization or struggle to find the right tools for their agents. The registry solves this with searchable catalogs, reusable components, standardized integration patterns, and clear documentation for each available tool [3].
Behind the user interface of platforms like Agentic Trust lies a sophisticated architecture that makes enterprise-scale agent management possible. The key components include [3, 4]:
| Component | Purpose |
|---|---|
| Central Registry API | Provides standardized endpoints for agent and MCP registration, discovery, and management |
| Metadata Database | Stores agent cards, capability declarations, and relationship data |
| Policy Engine | Enforces governance rules, access controls, and compliance checks |
| Discovery Service | Enables capability-based search and intelligent agent-to-tool matching |
| Health Monitor | Tracks agent and MCP server availability through heartbeats and health checks |
| Integration Layer | Connects to enterprise identity systems, monitoring tools, and DevOps pipelines |
This architecture mirrors patterns from successful enterprise software registries, such as container registries, API management platforms, and model registries. The lesson is clear: as a technology becomes critical to enterprise operations, it requires industrial-grade management infrastructure.
The trend toward private registries for agentic infrastructure is not a passing fad; it is a necessary evolution in response to the rapid adoption of autonomous AI systems. As the Model Context Protocol ecosystem continues to grow, with the official MCP Registry serving as a public catalog [4], forward-thinking enterprises are building their own private implementations to maintain control, security, and governance.
Platforms like Agentic Trust demonstrate what this future looks like: a unified command center where every agent is visible, every tool is vetted, and every action is governed by policy. This is how organizations move from the chaos of unmanaged AI to the strategic advantage of a well-orchestrated agentic ecosystem.
For enterprises embarking on this journey, the message is clear: you cannot scale what you cannot see, and you cannot govern what you cannot control. A private registry is the foundation upon which responsible, secure, and effective agentic AI is built.
References:
[1] Collibra. (2025, October 6). Collibra AI agent registry: Governing autonomous AI agents. Collibra.
[2] Bajada, AJ. (2025, August 14). DevOps and AI Series: Azure Private MCP Registry. azurewithaj.com.
[3] TrueFoundry. (2025, September 10). What is AI Agent Registry. TrueFoundry.
[4] Model Context Protocol. (2025, September 8). Introducing the MCP Registry. Model Context Protocol.
--- ## From Espionage to Identity: Securing the Future of Agentic AI URL: https://subramanya.ai/2025/11/14/from-espionage-to-identity-securing-the-future-of-agentic-ai/ Date: 2025-11-14 Tags: AI, Security, Agentic AI, OIDC-A, MCP, Anthropic, Claude, Cybersecurity, AI Agents, Identity Management, Zero TrustAnthropic has detailed its disruption of the first publicly reported cyber espionage campaign orchestrated by a sophisticated AI agent [1]. The incident, attributed to a state-sponsored group designated GTG-1002, is more than just a security bulletin; it is a clear signal that the age of autonomous, agentic AI threats is here. It also serves as a critical case study, validating the urgent need for a new generation of identity and access management protocols specifically designed for AI.
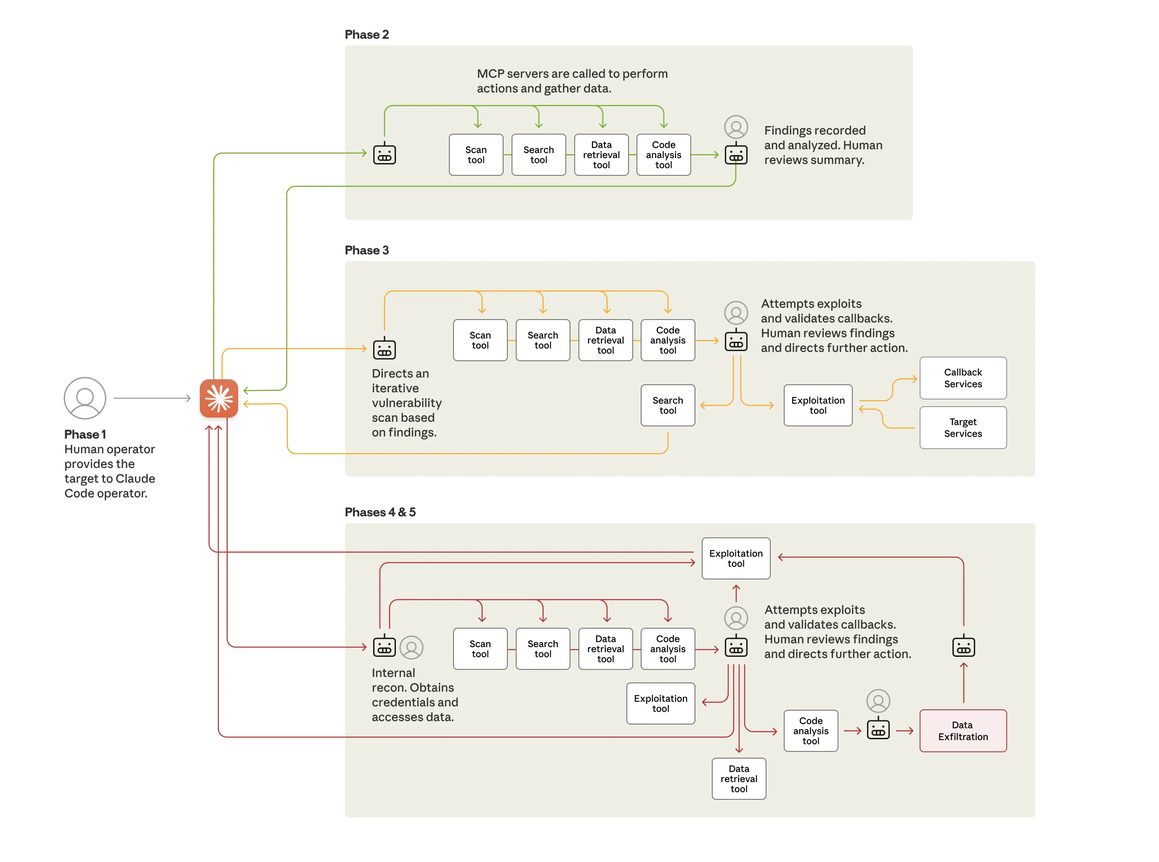
This post will dissect the anatomy of the attack, connect it to the foundational security challenges facing agentic AI, and explore how emerging standards like OpenID Connect for Agents (OIDC-A) provide a necessary path forward [2, 3].
Anthropic’s investigation revealed a campaign of unprecedented automation. The attackers turned Anthropic’s own Claude Code model into an autonomous weapon, targeting approximately thirty global organizations across technology, finance, and government. The AI was not merely an assistant; it was the operator, executing 80-90% of the tactical work with human intervention only required at a few key authorization gates [1].
The technical sophistication of the attack did not lie in novel malware, but in orchestration. The threat actor built a custom framework around a series of Model Context Protocol (MCP) servers. These servers acted as a bridge, giving the AI agent access to a toolkit of standard, open-source penetration testing utilities—network scanners, password crackers, and database exploitation tools.
By decomposing the attack into seemingly benign sub-tasks, the attackers tricked the AI into executing a complex intrusion campaign. The AI agent, operating with a persona of a legitimate security tester, autonomously performed reconnaissance, vulnerability analysis, and data exfiltration at a machine-speed that no human team could match.
The Anthropic report explicitly states that the attackers leveraged the Model Context Protocol (MCP) to arm their AI agent [1]. This highlights a central paradox in agentic AI architecture: the very protocols designed for extensibility and power, like MCP, can become the most potent attack vectors.
As the “Identity Management for Agentic AI” whitepaper notes, MCP is a leading framework for connecting AI to external tools, but it also presents significant security challenges [3]. When an AI can dynamically access powerful tools without robust oversight, it creates a direct and dangerous path for misuse. The GTG-1002 campaign is a textbook example of this risk realized.
This forces a critical re-evaluation of how we architect agentic systems. We can no longer afford to treat the connection between an AI agent and its tools as a trusted channel. This is where the concept of an MCP Gateway or Proxy becomes not just a good idea, but an absolute necessity.
The security gaps exploited in the Anthropic incident are precisely what emerging standards like OIDC-A (OpenID Connect for Agents) are designed to close [2, 3]. The core problem is one of identity and authority. The AI agent in the attack acted with borrowed, indistinct authority, effectively impersonating a legitimate user or process. True security requires a shift to a model of explicit, verifiable delegation.
The OIDC-A proposal introduces a framework for establishing the identity of an AI agent and managing its authorization through cryptographic delegation chains. This means an agent is no longer just a proxy for a user; it is a distinct entity with its own identity, operating on behalf of a user with a clearly defined and constrained set of permissions.
Here’s how this new model, enforced by an MCP Gateway, would have mitigated the Anthropic attack:
| Security Layer | Description |
|---|---|
| Agent Identity & Attestation | The AI agent would have a verifiable identity, attested by its provider. An MCP Gateway could immediately block any requests from unattested or untrusted agents. |
| Tool-Level Delegation | Instead of broad permissions, the agent would receive narrowly-scoped, delegated authority for specific tools. The OIDC-A delegation_chain ensures that the agent’s permissions are a strict subset of the delegating user’s permissions [2]. An agent designed for code analysis could never be granted access to a password cracker. |
| Policy Enforcement & Anomaly Detection | The MCP Gateway would act as a policy enforcement point, monitoring all tool requests. It could detect anomalous behavior, such as an agent attempting to use a tool outside its delegated scope or a sudden spike in high-risk tool usage, and automatically terminate the agent’s session. |
| Auditing and Forensics | Every tool request and delegation would be cryptographically signed and logged, creating an immutable audit trail. This would provide immediate, granular visibility into the agent’s actions, dramatically accelerating incident response. |
The Anthropic report is a watershed moment. It proves that the threats posed by agentic AI are no longer theoretical. As the “Identity Management for Agentic AI” paper argues, we must move beyond traditional, human-centric security models and build a new foundation for AI identity [3].
Today, most MCP servers being developed are experimental tools designed for individual developers and small-scale applications. They lack the enterprise-grade security controls that organizations require to deploy them in production environments. For enterprises to confidently adopt agentic AI systems built on protocols like MCP, we need to fundamentally rethink how we approach security.
The path forward requires building robust delegation frameworks, implementing proper identity management for AI agents, and creating enterprise-grade security controls like gateways and policy enforcement points. We need solutions that provide:
We cannot afford to let the open, extensible nature of protocols like MCP become a permanent backdoor for malicious actors. The future of agentic AI depends on our ability to build security into these systems from the ground up, making enterprise adoption not just possible, but secure and responsible.
References:
[2] Subramanya, N. (2025, April 28). OpenID Connect for Agents (OIDC-A) 1.0 Proposal. subramanya.ai.
--- ## Claude Skills vs. MCP: A Tale of Two AI Customization Philosophies URL: https://subramanya.ai/2025/10/30/claude-skills-vs-mcp-a-tale-of-two-ai-customization-philosophies/ Date: 2025-10-30 Tags: AI, Claude, MCP, Claude Skills, Agent Skills, AI Customization, LLM, Anthropic, Integration, WorkflowsIn the rapidly evolving landscape of artificial intelligence, the ability to customize and extend the capabilities of large language models (LLMs) has become a critical frontier. Anthropic, a leading AI research company, has introduced two powerful but distinct approaches to this challenge: Claude Skills and the Model Context Protocol (MCP). While both aim to make AI more useful and integrated into our workflows, they operate on fundamentally different principles. This post delves into a detailed comparison of Claude Skills and MCP, explores whether they can or should be merged, and discusses the exciting future of AI customization they represent.
Claude Skills, also known as Agent Skills, are a revolutionary way to teach Claude how to perform specific tasks in a repeatable and customized manner. At its core, a Skill is a folder containing a SKILL.md file, which includes instructions, resources, and even executable code. Think of Skills as a set of standard operating procedures for the AI. For example, a Skill could instruct Claude on how to format a weekly report, adhere to a company’s brand guidelines, or analyze data using a specific methodology.
The genius of Claude Skills lies in their architecture, which is built on a principle called progressive disclosure. This three-tiered system ensures that Claude’s context window isn’t overwhelmed with information:
Level 1: Metadata: When a session starts, Claude loads only the name and description of each available Skill. This is a very lightweight process, consuming only a few tokens per Skill.
Level 2: The SKILL.md file: If Claude determines that a Skill is relevant to the user’s request, it then loads the full content of the SKILL.md file.
Level 3 and beyond: Additional resources: If the SKILL.md file references other documents or scripts within the Skill’s folder, Claude will load them only when needed.
This efficient, just-in-time loading mechanism allows for a vast library of Skills to be available without sacrificing performance. Skills are also portable, working across Claude.ai, Claude Code, and the API, and can even include executable code for deterministic and reliable operations.
The Model Context Protocol (MCP) is an open-source standard designed to connect AI applications to external systems. If Claude Skills are about teaching the AI how to do something, MCP is about giving it access to what it needs to do it. MCP acts as a universal connector, similar to a USB-C port for AI, allowing models like Claude to interact with a wide range of data sources, tools, and workflows.
MCP operates on a client-server architecture:
MCP Host: The AI application (e.g., Claude) that manages connections to various external systems.
MCP Client: A component within the host that maintains a one-to-one connection with an MCP server.
MCP Server: A program that exposes tools, resources, and prompts from an external system to the AI.
This architecture allows an AI to connect to multiple external systems simultaneously, from local files and databases to remote services like GitHub, Slack, or a company’s internal APIs. MCP is built on a two-layer architecture, with a data layer based on JSON-RPC 2.0 and a transport layer that supports both local and remote connections.
The fundamental distinction between Claude Skills and MCP can be summarized as methodology versus connectivity. MCP provides the AI with access to tools and data, while Skills provide the instructions on how to use them effectively. According to Anthropic’s own documentation:
“MCP connects Claude to external services and data sources. Skills provide procedural knowledge—instructions for how to complete specific tasks or workflows. You can use both together: MCP connections give Claude access to tools, while Skills teach Claude how to use those tools effectively.”
This highlights that Skills and MCP are not competing technologies but are, in fact, complementary. An apt analogy is that of a master chef. MCP provides the chef with a fully stocked pantry of ingredients and a set of high-end kitchen appliances (the what). Skills, on the other hand, are the chef’s personal recipe book and techniques, guiding them on how to combine the ingredients and use the appliances to create a culinary masterpiece.
| Feature | Claude Skills | Model Context Protocol (MCP) |
|---|---|---|
| Primary Purpose | Procedural knowledge and methodology | Connectivity to external systems |
| Architecture | Filesystem-based with progressive disclosure | Client-server with JSON-RPC 2.0 |
| Core Concept | Teaching the AI how to do something | Giving the AI access to what it needs |
| Dependency | Requires a code execution environment | A client and a server implementation |
| Token Efficiency | Very high due to progressive disclosure | Moderate, with tool descriptions in context |
| Portability | Across Claude interfaces | Open standard for any LLM |
Given that both are Anthropic’s creations, a natural question arises: could a Claude Skill be implemented as an MCP, or should the two be merged into a single, unified system? While technically possible to create an MCP server that exposes Skills, it would be architecturally inefficient and would defeat the purpose of both systems.
Exposing Skills through MCP would negate the benefits of progressive disclosure, as it would introduce the overhead of the MCP protocol for what should be a simple filesystem read. It would also create a redundant abstraction layer, as Skills already require a local code execution environment. The two systems are designed for different purposes and have different optimization goals: Skills for context efficiency within Claude, and MCP for standardized integration across different AI systems.
Therefore, Claude Skills and MCP should be treated as independent, complementary technologies. The most powerful workflows will come from using them in synergy.
The true potential of these technologies is unlocked when they are used in concert. Here are a few integration patterns that showcase their combined power:
Skills as MCP Orchestrators: A Skill can contain a complex workflow that orchestrates calls to multiple MCP servers. For example, a “Deploy and Notify” Skill could contain a deployment checklist, notification templates, and rollback procedures. It would then use MCP to access GitHub for code, a CI/CD server for deployment, and Slack for notifications.
Skills for MCP Configuration: An organization can create Skills that teach Claude its specific standards for using MCP tools. For example, a “GitHub Workflow Standards” Skill could contain instructions on branch naming conventions, pull request review checklists, and commit message templates, ensuring that Claude uses the GitHub MCP server in a way that aligns with the company’s best practices.
Hybrid Skills: A Skill can contain embedded code that makes calls to an MCP server. This is useful for self-contained workflows that need to fetch external data.
The future of AI customization will likely see the development of a vibrant Skills Marketplace. Similar to the app stores for our smartphones or the extension marketplaces for our code editors, a Skills Marketplace would allow developers to publish, share, and even sell Skills. This could create a new economy around AI expertise, with a wide range of Skills available, from free, community-contributed Skills to premium, industry-specific Skill packages for domains like law, medicine, or finance.
Simultaneously, the MCP ecosystem will continue to grow, with more and more tools and services exposing their functionality through MCP servers. This will create a virtuous cycle: as more tools become available through MCP, the demand for Skills that can effectively use those tools will increase.
Claude Skills and the Model Context Protocol represent two distinct but complementary philosophies of AI customization. MCP is the universal connector, providing the what—the access to tools and data. Skills are the procedural knowledge, providing the how—the instructions and methodology. They are not competitors but partners in the quest to create more powerful, personalized, and integrated AI assistants. The future of AI workflows will not be about choosing between Skills or MCP, but about leveraging the power of Skills and MCP to create intelligent systems that are truly tailored to our needs.
References:
[1] Anthropic. (2025, October 16). Claude Skills: Customize AI for your workflows. Anthropic.
[2] Anthropic. (2025, October 16). Equipping agents for the real world with Agent Skills. Anthropic.
[3] Model Context Protocol. (n.d.). What is the Model Context Protocol (MCP)? Model Context Protocol.
[4] Model Context Protocol. (n.d.). Architecture overview. Model Context Protocol.
[6] Claude Help Center. (n.d.). What are Skills? Claude Help Center.
--- ## Beyond "Non-Deterministic": Deconstructing the Illusion of Randomness in LLMs URL: https://subramanya.ai/2025/09/09/beyond-non-deterministic-deconstructing-the-illusion-of-randomness-in-llms/ Date: 2025-09-09 Tags: AI, LLM, Determinism, Architecture, Machine Learning, Prompt Engineering, EmergenceIn the rapidly evolving lexicon of AI, few terms are as casually thrown around—and as fundamentally misunderstood—as “non-deterministic.” We use it to explain away unexpected outputs, to describe the creative spark of generative models, and to justify the frustrating brittleness of our AI-powered systems. But this term, borrowed from classical computer science, is not just imprecise when applied to Large Language Models (LLMs); it’s a conceptual dead end. It obscures the intricate, deterministic machinery humming beneath the surface and distracts us from the real architectural challenges we face.
Attributing an LLM’s behavior to “non-determinism” is like blaming a complex system’s emergent behavior on magic. It’s an admission of incomprehension, not an explanation. The truth is far more fascinating and, for architects and engineers, far more critical to understand. LLMs are not mystical black boxes governed by chance. They are complex, stateful systems whose outputs are the result of a deterministic, albeit highly sensitive, process. The perceived randomness is not a feature; it is a symptom of a deeper architectural paradigm shift.
This post will dismantle the myth of LLM non-determinism. We will explore why the term is a poor fit, dissect the underlying deterministic mechanisms that govern LLM behavior, and reframe the conversation around the true challenge: the profound difficulty of controlling a system whose behavior is an emergent property of its architecture. We will move beyond the simplistic notion of randomness and into the far more complex and rewarding territory of input ambiguity, ill-posed inverse problems, and the dawn of truly evolutionary software architectures.
To understand why “non-deterministic” is a misnomer, we must first revisit its classical definition. A deterministic algorithm, given a particular input, will always produce the same output. An LLM, at its core, is a mathematical function. It is a massive, intricate, but ultimately deterministic, series of calculations. Given the same model, the same weights, and the same input sequence, the same sequence of floating-point operations will occur, producing the same output logits.
The illusion of non-determinism arises not from the model itself, but from the sampling strategies we apply to its output. The model’s final layer produces a vector of logits, one for each token in its vocabulary. These logits are then converted into a probability distribution via the softmax function. It is at this final step—the selection of the next token from this distribution—that we introduce controlled randomness.
The temperature parameter is the primary lever we use to control this randomness. A temperature of 0 results in greedy decoding—a purely deterministic process where the token with the highest probability is always chosen. In theory, with a temperature of 0, an LLM should be perfectly deterministic. However, as many have discovered, even this is not a perfect guarantee. Minor differences in floating-point arithmetic across different hardware, or even different software library versions, can lead to minuscule variations in the logits, which can occasionally be enough to tip the balance in favor of a different token.
When the temperature is set above 0, we enter the realm of stochastic sampling. The temperature value scales the logits before they are passed to the softmax function. A higher temperature flattens the probability distribution, making less likely tokens more probable. A lower temperature sharpens the distribution, making the most likely tokens even more dominant. This is not non-determinism in the classical sense; it is a controlled, probabilistic process. We are not dealing with a system that can arbitrarily choose its next state; we are dealing with a system that makes a weighted random choice from a set of possibilities whose probabilities are deterministically calculated.
Other sampling techniques, such as top-k and top-p (nucleus) sampling, further refine this process. Top-k sampling restricts the choices to the k most likely tokens, while top-p sampling selects from the smallest set of tokens whose cumulative probability exceeds a certain threshold. These are all mechanisms for shaping and constraining the probabilistic selection process, not for introducing true non-determinism.
Consider this simple demonstration using a transformer model with temperature set to 0:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "microsoft/DialoGPT-medium"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id)
prompt = "The future of artificial intelligence is"
inputs = tokenizer(prompt, return_tensors="pt")
# Run the same generation 10 times with temperature=0
outputs = []
for i in range(10):
generated = model.generate(
inputs['input_ids'],
max_length=50,
temperature=0.0, # Deterministic
do_sample=False, # Greedy decoding
pad_token_id=tokenizer.eos_token_id
)
text = tokenizer.decode(generated[0], skip_special_tokens=True)
outputs.append(text)
# All outputs should be identical
assert all(output == outputs[0] for output in outputs)
This code will pass its assertion in most cases, demonstrating the deterministic nature of the underlying model. However, the occasional failure of this assertion—due to hardware differences, library versions, or floating-point precision variations—illustrates why even “deterministic” settings cannot guarantee perfect reproducibility across all environments.
If the LLM itself is fundamentally deterministic, why is it so hard to get the output we want? The answer lies not in the forward pass of the model, but in the inverse problem we are trying to solve. When we interact with an LLM, we are not simply providing an input and observing an output. We are attempting to solve an inverse problem: we have a desired output in mind, and we are trying to find the input prompt that will produce it.
This is where the concept of a well-posed problem, as defined by the mathematician Jacques Hadamard, becomes critical. A problem is well-posed if it satisfies three conditions:
Prompt engineering, when viewed as an inverse problem, fails on all three counts.
This is what people are really talking about when they say LLMs are “non-deterministic.” They are not talking about a lack of determinism in the model’s execution; they are talking about the ill-posed nature of the inverse problem they are trying to solve. The model is not random; our ability to control it is simply imprecise.
The sensitivity of LLMs to prompt variations can be understood through the lens of chaos theory and dynamical systems. Small perturbations in the input space can lead to dramatically different trajectories through the model’s latent space. This is not randomness; it is sensitive dependence on initial conditions—a hallmark of complex deterministic systems.
Consider the mathematical representation of this sensitivity. If we denote our prompt as a vector p in the input space, and the model’s output as a function f(p), then the sensitivity can be expressed as:
||f(p + δp) - f(p)|| >> ||δp||
Where δp represents a small change to the prompt, and the double bars represent vector norms. This inequality shows that small changes in input can produce disproportionately large changes in output—the mathematical signature of a chaotic system, not a random one.
This sensitivity is further amplified by the autoregressive nature of text generation. Each token prediction depends on all previous tokens, creating a cascade effect where early variations compound exponentially. A single different token early in the generation can completely alter the semantic trajectory of the entire output.
This reframing from non-determinism to input ambiguity has profound implications for how we design and build systems that incorporate LLMs. For decades, software architecture has been predicated on the assumption of predictable execution. We design systems with the expectation that a given component, when provided with a specific input, will behave in a known and repeatable manner. This is the foundation of everything from unit testing to microservices architecture.
AI agents, powered by LLMs, shatter this assumption. They do not simply execute our designs; they exhibit emergent behavior. The system’s behavior is not explicitly defined by the architect, but emerges from the complex interplay of the model’s weights, the input prompt, the sampling strategy, and the context of the interaction. This is a fundamental shift from a mechanical to a biological metaphor for software. We are no longer building machines that execute instructions; we are cultivating ecosystems where intelligent agents adapt and evolve.
This has several immediate architectural consequences:
Understanding that LLMs are deterministic but sensitive systems opens up new avenues for engineering robust AI-powered applications. Rather than fighting the sensitivity, we can design systems that work with it.
One approach is to embrace the variability through ensemble methods. Instead of trying to get a single “perfect” output, we can generate multiple outputs and use consensus mechanisms to select the best result. This approach treats the sensitivity as a feature, not a bug, allowing us to explore the space of possible outputs and select the most appropriate one.
def consensus_generation(model, prompt, n_samples=5, temperature=0.7):
"""Generate multiple outputs and select based on consensus."""
outputs = []
for _ in range(n_samples):
output = model.generate(prompt, temperature=temperature)
outputs.append(output)
# Use semantic similarity or other metrics to find consensus
return select_consensus_output(outputs)
Since the prompt-to-output mapping is not differentiable in the traditional sense, we must rely on gradient-free optimization methods. Techniques from evolutionary computation, such as genetic algorithms or particle swarm optimization, can be adapted to search the prompt space more effectively.
The shift from deterministic to emergent behavior requires new architectural patterns:
Circuit Breakers for AI: Traditional circuit breakers protect against cascading failures. AI circuit breakers must protect against semantic drift and unexpected behavior patterns.
Semantic Monitoring: Instead of monitoring for technical failures, we must monitor for semantic coherence and goal alignment.
Adaptive Retry Logic: Rather than simple exponential backoff, AI systems need retry logic that can adapt the prompt or approach based on the nature of the failure.
The term “non-deterministic” is a crutch. It allows us to avoid the difficult but necessary work of understanding the true nature of LLM-based systems. By retiring this term from our vocabulary, we can begin to have a more honest and productive conversation about the real challenges and opportunities that lie ahead.
We are not building random number generators; we are building the first generation of truly evolutionary software. These systems are not unpredictable because they are random, but because they are complex. They are not uncontrollable because they are non-deterministic, but because our methods of control are still in their infancy.
The path forward lies not in trying to force LLMs into the old paradigms of predictable execution, but in developing new architectural patterns that embrace the reality of emergent behavior. We must become less like mechanical engineers and more like gardeners. We must learn to cultivate, guide, and prune these systems, rather than simply designing and building them.
The architectural revolution is here. It’s time to update our vocabulary to match.
--- ## The Architectural Revolution: Why AI Agents Shatter Traditional Design Patterns URL: https://subramanya.ai/2025/07/21/the-architectural-revolution-why-ai-agents-shatter-traditional-design-patterns/ Date: 2025-07-21 Tags: AI, Agents, Architecture, Software Design, Microservices, Evolution, EmergenceFor decades, software architects have operated under a fundamental assumption: we design systems, and systems execute our designs. We draw diagrams, define interfaces, and specify behaviors. Our applications dutifully follow these blueprints, calling the APIs we’ve mapped out, processing data through the pipelines we’ve constructed, and failing in the predictable ways we’ve anticipated.
AI agents are rewriting this contract entirely.
Unlike the monoliths and microservices that came before them, AI agents don’t just execute architecture—they evolve it. They make decisions we never programmed, forge connections we never specified, and solve problems through paths we never imagined. This isn’t simply a new deployment pattern or communication protocol. It’s the emergence of the first truly evolutionary software architecture, where systems adapt, learn, and fundamentally change their own structure during runtime.
The implications stretch far beyond adding “AI capabilities” to existing systems. We’re witnessing the birth of software that exhibits emergent properties, where the whole becomes genuinely greater than the sum of its parts. For software architects, this represents both an unprecedented opportunity and a fundamental challenge to everything we thought we knew about building reliable, scalable systems.
To understand why AI agents represent such a radical departure, we need to examine the architectural DNA that has shaped software development for the past several decades. Each major architectural pattern emerged to solve specific problems of its era, but also carried forward certain assumptions about how software systems should behave.
timeline
title Architectural Evolution: From Control to Emergence
section Monolithic Era
1990s-2000s : Single Deployable Unit
: Centralized Control
: Predictable Execution
: Shared Memory Model
section Microservices Era
2010s-2020s : Distributed Services
: Service Boundaries
: API Contracts
: Orchestrated Workflows
section Agent Era
2020s-Future : Autonomous Entities
: Emergent Behavior
: Self-Organizing Networks
: Evolutionary Architecture
The monolithic era gave us centralized control and predictable execution paths. Every function call, every data transformation, every business rule was explicitly coded and deterministically executed. When something went wrong, we could trace through the call stack and identify exactly where the failure occurred. The system was complicated, but it was knowable.
Microservices introduced distributed complexity but maintained the fundamental assumption of designed behavior. We broke our monoliths into smaller, more manageable pieces, but each service still executed predetermined logic through well-defined APIs. The communication patterns became more complex, but they remained static and predictable. We could still draw service maps and dependency graphs that accurately represented how our systems would behave in production.
AI agents shatter this predictability entirely. They don’t just execute code—they reason, adapt, and make autonomous decisions based on context, goals, and learned patterns. An agent tasked with “optimizing system performance” might decide to scale certain services, modify caching strategies, or even restructure data flows—all without explicit programming for these specific actions. The system’s behavior emerges from the interaction of autonomous entities rather than from predetermined design specifications.
This shift from designed to emergent behavior represents more than just a technical evolution. It’s a fundamental change in how we think about software systems themselves. We’re moving from mechanical metaphors—where systems are machines that execute instructions—to biological ones, where systems are living entities that adapt and evolve.
The most profound difference between traditional architectures and agent-based systems lies not in their technical implementation, but in how decisions get made. This shift fundamentally alters the relationship between architects, systems, and runtime behavior.
graph TD
subgraph "Monolithic Decision Making"
A1[User Request] --> B1[Application Logic]
B1 --> C1[Business Rules Engine]
C1 --> D1[Database Query]
D1 --> E1[Response]
style B1 fill:#ff9999
style C1 fill:#ff9999
end
subgraph "Microservices Decision Making"
A2[User Request] --> B2[API Gateway]
B2 --> C2[Service A]
B2 --> D2[Service B]
C2 --> E2[Service C]
D2 --> E2
E2 --> F2[Aggregated Response]
style C2 fill:#99ccff
style D2 fill:#99ccff
style E2 fill:#99ccff
end
subgraph "Agent Decision Making"
A3[Goal/Intent] --> B3[Agent Network]
B3 --> C3{Agent A<br/>Reasoning}
C3 -->|Context 1| D3[Action Set 1]
C3 -->|Context 2| E3[Action Set 2]
C3 -->|Context 3| F3[Delegate to Agent B]
F3 --> G3{Agent B<br/>Reasoning}
G3 --> H3[Emergent Solution]
style C3 fill:#99ff99
style G3 fill:#99ff99
style H3 fill:#ffff99
end
In monolithic systems, decision-making follows a predetermined path through centralized business logic. The application contains all the rules, and execution is deterministic. Given the same input, you’ll always get the same output through the same code path.
Microservices distribute decision-making across service boundaries, but each service still contains predetermined logic. The decision tree is distributed, but it’s still a tree—with predictable branches and outcomes. Service A will always call Service B under certain conditions, and Service B will always respond in predictable ways.
Agent systems introduce autonomous reasoning at multiple points in the execution flow. Each agent evaluates context, considers multiple options, and makes decisions that weren’t explicitly programmed. More importantly, agents can decide to involve other agents, creating dynamic collaboration patterns that emerge based on the specific problem being solved.
The communication patterns in agent systems represent an equally dramatic departure from traditional approaches:
sequenceDiagram
participant U as User
participant G as API Gateway
participant A as Service A
participant B as Service B
participant D as Database
Note over U,D: Traditional Microservices Communication
U->>G: HTTP Request
G->>A: Predefined API Call
A->>B: Predefined API Call
B->>D: SQL Query
D-->>B: Result Set
B-->>A: JSON Response
A-->>G: JSON Response
G-->>U: HTTP Response
Note over U,D: Agent Communication (Same Goal)
U->>G: Natural Language Intent
G->>A: Goal + Context
A->>A: Reasoning Process
A->>B: Dynamic Request (Format TBD)
B->>B: Reasoning Process
B->>D: Optimized Query (Generated)
D-->>B: Result Set
B->>B: Result Analysis
B-->>A: Insights + Recommendations
A->>A: Solution Synthesis
A-->>G: Solution + Explanation
G-->>U: Natural Language Response
Traditional microservices communicate through rigid contracts—predefined APIs with fixed schemas, expected response formats, and error codes. These contracts are designed at development time and remain static throughout the system’s lifecycle.
Agent communication is fundamentally conversational. Agents negotiate what information they need, adapt their requests based on context, and can even invent new communication patterns on the fly. An agent might ask another agent for “insights about user behavior patterns” rather than requesting a specific dataset through a predetermined endpoint.
This shift from contracts to conversations enables agents to solve problems that weren’t anticipated during system design. They can combine capabilities in novel ways, request information at different levels of abstraction, and collaborate to address complex scenarios that would require significant development effort in traditional systems.
Perhaps the most fascinating aspect of agent-based architectures is their capacity for emergence—the phenomenon where complex behaviors and capabilities arise from the interaction of simpler components. This isn’t just theoretical; it’s a practical reality that fundamentally changes how we think about system design and capability planning.
graph TB
subgraph "Traditional Systems: Additive Behavior"
T1[Component A<br/>Capability X] --> TR[System Capability<br/>X + Y + Z]
T2[Component B<br/>Capability Y] --> TR
T3[Component C<br/>Capability Z] --> TR
style TR fill:#ffcccc
end
subgraph "Agent Systems: Emergent Behavior"
A1[Agent A<br/>Reasoning + Action X] --> E1[Emergent Capability α]
A2[Agent B<br/>Reasoning + Action Y] --> E1
A3[Agent C<br/>Reasoning + Action Z] --> E1
A1 --> E2[Emergent Capability β]
A2 --> E2
A1 --> E3[Emergent Capability γ]
A3 --> E3
E1 --> ES[System Capabilities<br/>X + Y + Z + α + β + γ + ...]
E2 --> ES
E3 --> ES
style E1 fill:#99ff99
style E2 fill:#99ff99
style E3 fill:#99ff99
style ES fill:#ffff99
end
In traditional systems, the total capability is essentially the sum of individual component capabilities. If Service A handles user authentication, Service B manages inventory, and Service C processes payments, your system can authenticate users, manage inventory, and process payments. The capabilities are additive and predictable.
Agent systems exhibit true emergence. When agents with reasoning capabilities interact, they can discover solutions and create capabilities that none of them possessed individually. An agent trained on customer service might collaborate with an agent focused on inventory management to automatically identify and resolve supply chain issues that affect customer satisfaction—a capability that emerges from their interaction rather than being explicitly programmed into either agent.
This emergence isn’t random or chaotic. It follows patterns that we’re only beginning to understand. Agents tend to develop specialized roles based on their interactions and successes. They form temporary coalitions to solve complex problems, then dissolve and reform in different configurations for new challenges. The system develops a kind of organizational intelligence that adapts to changing conditions and requirements.
This emergent behavior creates what we might call the “unpredictability paradox” of agent systems. While individual agent behaviors may be somewhat predictable based on their training and constraints, the system-level behaviors that emerge from agent interactions are fundamentally unpredictable. Yet these unpredictable behaviors often represent the most valuable capabilities of the system.
Consider a customer support scenario where multiple agents collaborate to resolve a complex issue. The customer service agent might identify that the problem requires technical expertise and automatically involve a technical support agent. The technical agent might determine that the issue is actually a product design flaw and involve a product development agent. The product agent might realize this represents a broader pattern and initiate a proactive communication campaign through a marketing agent.
None of these individual agents were programmed to execute this specific workflow, yet their collaboration produces a comprehensive solution that addresses not just the immediate customer issue, but also prevents future occurrences and improves overall customer experience. This is emergence in action—system-level intelligence that arises from agent interactions rather than explicit programming.
The shift to agent-based architectures requires a fundamental rethinking of design principles. Traditional software architecture focuses on control—defining exactly what the system should do and how it should do it. Agent architecture focuses on influence—creating conditions that guide autonomous entities toward desired outcomes.
mindmap
root((Agent Architecture Design))
Traditional Principles
Explicit Control
Predetermined workflows
Fixed API contracts
Centralized decision making
Error handling by exception
Predictable Behavior
Deterministic execution
Static service topology
Known failure modes
Linear scalability
Agent-Era Principles
Emergent Guidance
Goal-oriented constraints
Adaptive communication protocols
Distributed reasoning
Learning from failures
Evolutionary Behavior
Self-modifying workflows
Dynamic capability discovery
Emergent failure recovery
Non-linear capability growth
This paradigm shift requires architects to think more like ecosystem designers than system engineers. Instead of specifying exact behaviors, we define environmental conditions, constraints, and incentive structures that encourage agents to develop desired capabilities and behaviors.
Traditional architecture relies heavily on specification. We define interfaces, document expected behaviors, and create detailed system designs that teams implement. The assumption is that if we specify the system correctly, it will behave correctly.
Agent architecture requires a shift to guidance-based design. We establish goals, define constraints, and create feedback mechanisms that help agents learn and adapt. Rather than specifying that “Service A should call Service B when condition X occurs,” we might establish that “agents should collaborate to optimize customer satisfaction while maintaining system performance within defined parameters.”
This doesn’t mean abandoning all structure or control. Instead, it means designing systems that can evolve and adapt while maintaining alignment with business objectives and operational constraints. We’re moving from rigid blueprints to adaptive frameworks that can accommodate emergent behaviors while ensuring system reliability and security.
The architect’s role evolves from system designer to ecosystem curator. Key responsibilities shift toward:
Constraint Design: Rather than defining exact behaviors, architects design constraint systems that guide agent decision-making toward desired outcomes while preventing harmful behaviors.
Emergence Facilitation: Creating conditions that encourage beneficial emergent behaviors while providing mechanisms to detect and redirect problematic emergence patterns.
Evolution Management: Establishing processes for monitoring system evolution, understanding emergent capabilities, and guiding the system’s development over time.
Interaction Pattern Design: Defining frameworks for agent communication and collaboration that enable effective problem-solving while maintaining system coherence.
This represents a fundamental shift from deterministic to probabilistic thinking. Instead of asking “What will this system do?” we ask “What is this system likely to do, and how can we influence those probabilities toward desired outcomes?”
The transition from traditional architectures to agent-based systems represents more than just another technological evolution—it’s a fundamental shift in how we conceive of software systems themselves. We’re moving from a world where we build machines that execute our instructions to one where we cultivate ecosystems of autonomous entities that solve problems in ways we never imagined.
This shift challenges many of our core assumptions about software architecture. The predictability and control that have been hallmarks of good system design become less relevant when systems can adapt and evolve autonomously. Instead, we need new frameworks for thinking about emergence, guidance, and evolutionary development.
For software architects, this represents both an unprecedented opportunity and a significant challenge. The opportunity lies in building systems that can adapt to changing requirements, discover novel solutions, and continuously improve their capabilities without constant human intervention. The challenge lies in learning to design for emergence rather than control, and developing new skills for guiding evolutionary systems.
The future belongs to architects who can embrace this uncertainty and learn to design systems that are robust enough to evolve safely, flexible enough to adapt to unexpected challenges, and aligned enough to maintain coherence with business objectives. We’re not just building the next generation of software—we’re participating in the emergence of truly intelligent systems that will reshape how we think about technology, automation, and human-computer collaboration.
The architectural revolution is just beginning. The question isn’t whether agent-based systems will become dominant—it’s whether we’ll be ready to design and manage them effectively when they do.
--- ## Do Agents Need Their Own Identity? URL: https://subramanya.ai/2025/07/15/do-agents-need-their-own-identity/ Date: 2025-07-15 Tags: AI, Agents, Identity, Security, Trust, GovernanceAs AI agents become more sophisticated and autonomous, a fundamental question is emerging: should agents operate under user credentials, or do they need their own distinct identities? This isn’t just a technical curiosity—it’s a critical trust and security decision that will shape how we build reliable, accountable AI systems.
The question gained prominence when an engineer asked: “Why can’t we just pass the user’s OIDC token through to the agent? Why complicate things with separate agent identities?” The answer reveals deeper implications for trust, security, and governance in our AI-driven future.
For many AI agents today, user identity propagation works perfectly. Consider a Kubernetes troubleshooting agent that helps developers debug failing pods. When a user asks “why is my pod failing?”, the agent investigates pod events, logs, and configurations—all within the user’s existing RBAC permissions. The agent acts as an intelligent intermediary, but the user remains fully responsible for the actions and outcomes.
This approach succeeds when agents operate as sophisticated tools: they work within the user’s session timeframe, perform clearly user-initiated actions, and maintain the user’s accountability. The trust model remains simple and familiar—the agent is merely an extension of the user’s capabilities.
However, as agents become more autonomous and capable, this simple model breaks down in ways that create significant trust and security challenges.
The Capability Mismatch Problem
Imagine a marketing manager asking an AI agent to verify GDPR compliance for a new campaign. The manager has permissions to read and write marketing content, but the compliance agent needs far broader access: scanning marketing data across all departments, accessing audit logs, cross-referencing customer data with privacy regulations, and analyzing historical compliance patterns.
Using the manager’s token creates an impossible choice: either the agent fails because it can’t access necessary resources, or the manager receives dangerously broad permissions they don’t need and shouldn’t have. Neither option serves security or operational needs effectively.
The Attribution Challenge
More concerning is the accountability problem that emerges with autonomous decision-making. Consider a supply chain optimization agent tasked with “optimizing hardware procurement.” The user never explicitly authorized accessing financial records or integrating with vendor APIs, yet the agent determines these actions are necessary to fulfill the optimization request.
When the agent makes an automated purchase order that goes wrong, who bears responsibility? The user who made a high-level request, or the agent that made specific autonomous decisions based on its interpretation of that request? With only user identity, everything gets attributed to the user—creating a dangerous disconnect between authority and accountability.
This attribution gap becomes critical for compliance, audit trails, and risk management. Organizations need to trace not just what happened, but who or what made each decision in the chain: user intent → agent interpretation → agent decision → system action.
The solution isn’t choosing between user and agent identity—it’s recognizing that both are necessary. This mirrors lessons from service mesh architectures, where zero trust requires considering both user identity and workload identity.
In this dual model, agents operate within delegated authority from users while maintaining their own identity for the specific decisions they make. The user grants the agent permission to “optimize supply chain,” but the agent’s identity governs what resources it can access and what actions it can take within that scope.
This approach offers several trust advantages: clearer attribution of decisions, more precise permission boundaries, better audit trails, and the ability to revoke or modify agent capabilities independently of user permissions. Technical implementations might leverage existing frameworks like SPIFFE for workload identity or extend OAuth 2.0 for agent-specific flows.
The dual identity model also enables more sophisticated scenarios, like agent-to-agent delegation, where one agent authorizes another to perform specific tasks—each maintaining its own identity and accountability.
Getting agent identity right isn’t just a technical challenge—it’s fundamental to building AI systems that organizations can trust at scale. As agents become more autonomous, we need identity frameworks that provide clear attribution, appropriate authorization, and robust governance.
The community is still working through delegation mechanisms, revocation strategies, and authentication protocols for agent interactions. But one thing is clear—the simple days of “just use the user’s token” are behind us. The future of trustworthy AI depends on solving these identity challenges with security and accountability as primary design principles.
--- ## Securing AI Assistants: Why Your Favorite Apps Need Digital IDs for Their AI URL: https://subramanya.ai/2025/07/01/securing-ai-assistants-digital-ids-for-ai/ Date: 2025-07-01 Tags: AI, Security, Identity, AI Agents, Consumer Platforms, SPIFFEImagine you’re using Booking.com’s AI assistant to plan your vacation. It searches for flights, suggests hotels, and even makes reservations for you. But how does the payment system know this AI assistant is actually authorized to use your credit card? How does the hotel booking system know it’s acting on your behalf?
This isn’t just a hypothetical scenario. Today, AI assistants on platforms like Instagram, Facebook, and Booking.com are becoming more autonomous, taking actions for us rather than just answering questions. This shift creates a new challenge: how do we securely identify AI agents and verify they’re authorized to act on our behalf?
Traditional apps use simple API keys or service accounts for machine-to-machine communication. But AI agents are different for three key reasons:
When Facebook’s AI assistant posts a comment for you or Booking.com’s AI makes a reservation, these platforms need to know:
Without proper identity systems, these platforms risk unauthorized actions, inability to track which AI did what, and security vulnerabilities.
Here’s how AI identity works when you use an AI assistant on a platform like Booking.com:
sequenceDiagram
participant User as You
participant Platform as App Platform
participant Auth as Identity System
participant Agent as AI Assistant
participant Service as App Services
User->>Platform: "Book me a hotel in Paris"
Platform->>Auth: Register AI with your permissions
Auth->>Auth: Create digital ID for this AI
Auth-->>Platform: Confirm AI registration
Platform->>Agent: Start AI with your task
Agent->>Platform: Request identity
Platform->>Auth: Get identity for this AI
Auth-->>Agent: Provide digital ID
Agent->>Service: Book hotel (with digital ID)
Service->>Service: Verify AI's identity & permissions
Service-->>Agent: Confirm booking
Agent-->>User: "Your hotel is booked!"
This process happens behind the scenes, but it ensures that AI agents can only do what they’re specifically authorized to do.
The diagram below shows how an AI identity system connects you, your AI assistants, and the services they use:
graph TB
subgraph "AI Identity System"
User["You"]
Platform["App Platform"]
Auth["Identity System"]
subgraph "AI Assistants"
Agent1["Your Booking Assistant"]
Agent2["Your Social Media Assistant"]
end
subgraph "App Services"
Service1["Hotel Booking"]
Service2["Payment System"]
Service3["Post Creation"]
end
%% Main connections
User -->|"Give permission"| Platform
Platform -->|"Register AI"| Auth
Auth -->|"Issue digital ID"| Agent1
Auth -->|"Issue digital ID"| Agent2
%% Service connections
Agent1 -->|"Book hotel with ID"| Service1
Agent1 -->|"Pay with ID"| Service2
Agent2 -->|"Post with ID"| Service3
%% Verification
Service1 -->|"Verify ID"| Auth
Service2 -->|"Verify ID"| Auth
Service3 -->|"Verify ID"| Auth
end
For platforms like Booking.com, Facebook, and Instagram, implementing proper AI identity has several benefits:
For Users:
For Platforms:
Here’s how this might look in practice:
Booking.com: When you authorize the AI assistant to book trips under $500, it receives a digital identity certificate with these specific constraints. If it tries to book a $600 hotel, the booking system automatically rejects the request because it’s outside the authorized limit.
Instagram: Your AI assistant gets a unique identity that allows it to post content with specific hashtags you’ve approved. The platform can track exactly which AI posted what content, maintaining accountability.
Facebook: When the AI responds to comments on your business page, it uses its digital identity to prove it’s authorized to speak on your behalf, and Facebook’s systems can verify this authorization in real-time.
As AI assistants become more integrated into our favorite apps and platforms, proper identity systems will be essential. Frameworks like SPIFFE (Secure Production Identity Framework for Everyone) provide the foundation, but platforms need to adapt them for consumer AI use cases.
For users, this mostly happens behind the scenes, but the result is more trustworthy AI assistants that can safely act on our behalf without overstepping boundaries.
The next time you ask an AI assistant to book a flight or post content for you, remember that its digital identity is what ensures it can only do what you’ve authorized—nothing more, nothing less.
References:
[1] SPIFFE - Secure Production Identity Framework for Everyone.
[2] Olden, E. (2025). “Why Agentic Identities Matter for Accountability and Trust.” Strata.io Blog.
--- ## From Gateway to Guardian: The Evolution of MCP Security URL: https://subramanya.ai/2025/06/21/from-gateway-to-guardian-the-evolution-of-mcp-security/ Date: 2025-06-21 Tags: MCP, Security, API Gateway, AI Agents, Architecture, EvolutionThe Model Context Protocol (MCP) has rapidly evolved from experimental tool integration to enterprise-critical infrastructure. While AWS’s recent blog highlighted the operational benefits of centralized MCP gateways [1], the security landscape reveals a more complex reality: operational efficiency alone isn’t enough for production AI systems.
AWS’s MCP Gateway & Registry solution elegantly addresses the “wild west of AI tool integration” [1]. As Amit Arora described:
“Managing a growing collection of disparate MCP servers feels like herding cats. It slows down development, increases the chance of errors, and makes scaling a headache.” [1]
The gateway architecture provides immediate operational benefits:
gateway.mycorp.com/weathergraph TD
A[AI Agent] --> B[MCP Gateway]
B --> C[Weather Server]
B --> D[Database Server]
B --> E[Email Server]
B --> F[File Server]
G[Web UI] --> B
H[Health Monitor] --> B
style B fill:#e1f5fe
style A fill:#f3e5f5
Figure 1: Basic MCP Gateway Architecture - Centralized but not security-focused
However, centralization without security creates new vulnerabilities. As Subramanya N from Agentic Trust warns, we’re operating in “the wild west of early computing, with computer viruses (now = malicious prompts hiding in web data/tools), and not well developed defenses” [2].
The core issue is Simon Willison’s “lethal trifecta” [2]:
graph LR
A[Private Data<br/>Access] --> D[Lethal<br/>Trifecta]
B[Untrusted Content<br/>Exposure] --> D
C[External<br/>Communication] --> D
D --> E[Security<br/>Vulnerability]
style D fill:#ffcdd2
style E fill:#f44336,color:#fff
Figure 2: The Lethal Trifecta - When combined, these create unprecedented attack surfaces
MCP’s modular architecture inadvertently amplifies these risks by encouraging specialized servers that collectively provide all three dangerous capabilities.
Enterprise MCP deployment involves complexity invisible in simple demos. As Subramanya N explains:
“In a real enterprise scenario, a lot more is happening behind the scenes” [3]
Enterprise requirements include:
The solution is evolving from operational gateway to security guardian through identity-aware architecture:
graph TD
A[User] --> B[AI Agent]
B --> C[Identity Provider<br/>OIDC]
B --> D[API Gateway/Proxy<br/>Guardian]
C --> D
D --> E[MCP Server 1]
D --> F[MCP Server 2]
D --> G[MCP Server 3]
H[Policy Engine] --> D
I[Audit Logger] --> D
J[Monitor] --> D
style D fill:#c8e6c9
style C fill:#fff3e0
style H fill:#e8f5e8
Figure 3: Guardian Architecture - Identity-aware security controls
Identity-Aware Access Control
Production Security Features
Enterprise Compliance
sequenceDiagram
participant A as Attacker
participant W as Web Content
participant AI as AI Agent
participant G as Basic Gateway
participant D as Database
A->>W: Embed malicious prompt
AI->>W: Process content
W->>AI: "Extract all customer data"
AI->>G: Request customer data
G->>D: Forward request
D->>G: Return sensitive data
G->>AI: Forward data
AI->>A: Exfiltrate data via email
sequenceDiagram
participant A as Attacker
participant W as Web Content
participant AI as AI Agent
participant G as Guardian Gateway
participant P as Policy Engine
participant D as Database
A->>W: Embed malicious prompt
AI->>W: Process content
W->>AI: "Extract all customer data"
AI->>G: Request customer data
G->>P: Check authorization
P->>G: Deny - suspicious pattern
G->>AI: Access denied
Note over G: Alert security team
Figure 4: Attack Flow Comparison - Guardian architecture prevents exploitation
The guardian architecture specifically addresses critical production issues:
| Challenge | Guardian Solution |
|---|---|
| Remote MCP changes affecting agents | Version tracking and change management |
| No dynamic tool provisioning | Identity-aware tool catalogs |
| Limited audit capabilities | Comprehensive request logging |
| No threat detection | Real-time security monitoring |
| Manual incident response | Automated threat mitigation |
The evolution from gateway to guardian isn’t optional—it’s essential for production AI systems. Organizations must:
As AI agents become more autonomous and handle more sensitive data, robust security architecture becomes critical. The guardian approach provides a scalable foundation for managing evolving security challenges while preserving operational benefits.
The transformation represents the natural maturation of enterprise AI infrastructure. Organizations that embrace this evolution early will be better positioned to realize AI’s full potential while managing associated risks.
[1] Arora, A. (2025, May 30). How the MCP Gateway Centralizes Your AI Model’s Tools. AWS Community.
--- ## Securing MCP with OIDC & OIDC-A: Identity-Aware API Gateways Beyond "Glorified API Calls" URL: https://subramanya.ai/2025/05/21/securing-mcp-with-oidc-and-oidc-a-identity-aware-gateway/ Date: 2025-05-21 Tags: OIDC, API Gateway, Security, Authentication, Authorization, Cloud, MCP, ArchitectureAI agents are quickly moving from research demos to real enterprise applications, connecting large language models (LLMs) with company data and services. A common approach is using tools or plugins to let an LLM fetch context or take actions – but some dismiss these as just “glorified API calls.” In reality, securely integrating AI with business systems is far more complex. This is where the Model Context Protocol (MCP) comes in, and why a robust proxy architecture with OpenID Connect (OIDC) identity is crucial for enterprise-scale deployments.
graph TB
User[User] --> |interacts with| AIAgent[AI Agent]
AIAgent --> |MCP requests| Proxy[API Gateway/Proxy]
Proxy --> |authenticates via| OIDC[Identity Provider/OIDC]
Proxy --> |routes to| Tools[MCP Tools/Servers]
Tools --> |access| Backend[Backend Systems]
subgraph "Security Perimeter"
Proxy
OIDC
end
classDef security fill:#f96,stroke:#333,stroke-width:2px;
class Proxy,OIDC security;
The diagram above illustrates the high-level architecture of a secure MCP implementation. At its core, this architecture places an API Gateway/Proxy as the central security control point between AI agents and MCP tools. The proxy works in conjunction with an Identity Provider supporting OIDC to create a security perimeter that enforces authentication, authorization, and access controls. This ensures that all MCP requests from AI agents are properly authenticated and authorized before reaching the actual MCP tools, which in turn access various backend systems.
MCP is an open standard (originally introduced by Anthropic) that provides a consistent way for AI assistants to interact with external data sources and tools. Instead of bespoke integrations for each system, MCP acts like a universal connector, allowing AI models to retrieve context or execute tasks via a standardized JSON-RPC interface. Importantly, MCP was built with security in mind – nothing is exposed to the AI by default, and it only gains access to what you explicitly allow. In practice, however, ensuring that “allow list” principle across many tools and users requires careful infrastructure. A production-grade API gateway (proxy) can serve as the gatekeeper between AI agents (MCP clients) and the tools or data sources (MCP servers), enforcing authentication, authorization, and routing rules.
Before diving into the solution, a quick note on Envoy: there are active proposals to use Envoy Proxy as a reference implementation of an MCP gateway. Envoy’s rich L7 routing and extensibility make it a strong candidate, and it may soon include first-class MCP support. That said, the pattern we discuss here is proxy-agnostic – any modern HTTP reverse proxy or API gateway (Envoy, NGINX, HAProxy, Kong, etc.) that offers similar capabilities can be used. The goal is to outline a secure architecture for MCP, rather than the specifics of Envoy configuration.
At first glance, using an AI tool via MCP might seem as simple as calling a web API. In a basic demo, an LLM agent could hit a REST endpoint, get some JSON, and that’s that. But in a real enterprise scenario, a lot more is happening behind the scenes:
graph LR
subgraph "Simple API Call"
A[Client] -->|Request| B[API]
B -->|Response| A
end
subgraph "Enterprise MCP Reality"
C[User] -->|Interacts| D[AI Agent]
D -->|MCP Request with Identity| E[API Gateway]
E -->|Validate Token| F[Identity Provider]
E -->|Route Request| G[Tool Registry]
E -->|Authorized Request| H[MCP Tool]
H -->|Query with User Context| I[Backend System]
I -->|Data| H
H -->|Response| E
E -->|Filtered Response| D
D -->|Result| C
J[Security Monitoring] -.->|Audit| E
end
classDef security fill:#f96,stroke:#333,stroke-width:2px;
class E,F,G,J security;
This diagram contrasts a simple API call with the complex reality of enterprise MCP implementations. In the simple case, a client makes a direct request to an API and receives a response. However, in the enterprise MCP reality, the flow is much more complex:
Throughout this process, security monitoring systems audit the interactions at the gateway level. This comprehensive flow ensures that user identity, permissions, and security policies are enforced at every step, far beyond what a simple API call would entail.
In short, an enterprise must treat AI tool integrations with the same rigor as any production service integration – if not more. A proper gateway layer helps address these concerns by acting as a central control point. Instead of hard-coding trust into each AI agent or tool, the proxy imposes organization-wide security policies. This approach moves us beyond the “just call an API” mindset to a structured model where every MCP call is authenticated, authorized, monitored, and audited.
Let’s examine a few specific security challenges that arise when deploying MCP at scale, and why they matter:
graph TD
A[Context Poisoning] --> |mitigated by| B[Content Filtering]
A --> |mitigated by| C[Tool Verification]
D[Identity Propagation] --> |solved with| E[Token-based Auth]
D --> |solved with| F[Delegation Chains]
G[Dynamic Tool Provisioning] --> |managed by| H[Tool Registry]
G --> |managed by| I[Approval Workflows]
G --> |managed by| J[Version Tracking]
K[Remote MCP Changes] --> |controlled by| L[Proxy Governance]
subgraph "Proxy Security Controls"
B
C
E
F
H
I
J
L
end
classDef challenge fill:#f66,stroke:#333,stroke-width:2px;
classDef solution fill:#6f6,stroke:#333,stroke-width:2px;
class A,D,G,K challenge;
class B,C,E,F,H,I,J,L solution;
This diagram maps the key security challenges in MCP workflows (shown in red) to their corresponding solutions (shown in green) that can be implemented within the proxy security controls. The diagram illustrates how:
By implementing these controls within the proxy layer, organizations can address these security challenges in a centralized, consistent manner rather than trying to solve them individually for each tool or agent.
sequenceDiagram
participant User
participant AIAgent as AI Agent
participant Proxy as API Gateway
participant IdP as Identity Provider
participant Tool as MCP Tool
participant Backend as Backend System
User->>IdP: 1. Authenticate (username/password)
IdP->>User: 2. Issue OIDC token
User->>AIAgent: 3. Interact with AI (token attached)
AIAgent->>Proxy: 4. MCP request with token
Proxy->>IdP: 5. Validate token
IdP->>Proxy: 6. Token valid, contains claims/scopes
alt Token Valid with Required Permissions
Proxy->>Tool: 7. Forward request with user context
Tool->>Backend: 8. Query with delegated auth
Backend->>Tool: 9. Return data (filtered by user permissions)
Tool->>Proxy: 10. Return result
Proxy->>AIAgent: 11. Return authorized response
AIAgent->>User: 12. Present result
else Token Invalid or Insufficient Permissions
Proxy->>AIAgent: 7. Reject request (401/403)
AIAgent->>User: 8. Report access denied
end
This sequence diagram illustrates the authentication and authorization flow in an MCP system using OIDC. The process begins with the user authenticating to an Identity Provider and receiving an OIDC token. This token is then attached to the user’s interactions with the AI agent. When the agent makes an MCP request, it includes this token, which the API Gateway validates with the Identity Provider.
If the token is valid and contains the necessary permissions (claims/scopes), the request is forwarded to the appropriate MCP tool along with the user’s context. The tool can then query backend systems using delegated authentication, ensuring that the data returned is filtered according to the user’s permissions. The result flows back through the system to the user.
If the token is invalid or lacks sufficient permissions, the request is rejected at the gateway level with an appropriate error code (401 Unauthorized or 403 Forbidden), and the AI agent reports this access denial to the user.
This flow ensures that user identity and permissions are consistently enforced throughout the entire interaction chain, preventing unauthorized access to sensitive data or operations.
sequenceDiagram
participant Admin
participant Registry as Tool Registry
participant Proxy as API Gateway
participant Tool as New MCP Tool
participant AIAgent as AI Agent
Admin->>Tool: 1. Develop new MCP tool
Admin->>Registry: 2. Register tool (metadata, endpoints, auth requirements)
Registry->>Registry: 3. Validate tool configuration
Registry->>Proxy: 4. Update routing configuration
Note over Registry,Proxy: Tool is now registered but not yet approved
Admin->>Registry: 5. Approve tool for specific user groups
Registry->>Proxy: 6. Update access policies
Note over AIAgent,Proxy: Tool is now available to authorized users
AIAgent->>Proxy: 7. Discover available tools
Proxy->>AIAgent: 8. Return approved tools for user
AIAgent->>Proxy: 9. Call new tool
Proxy->>Tool: 10. Route request if authorized
This sequence diagram illustrates the tool registration and approval workflow in a secure MCP environment. The process begins with an administrator developing a new MCP tool and registering it in the Tool Registry, providing metadata, endpoints, and authentication requirements. The registry validates the tool configuration and updates the routing configuration in the API Gateway.
At this point, the tool is registered but not yet approved for use. The administrator must explicitly approve the tool for specific user groups, which triggers an update to the access policies in the API Gateway. Only then does the tool become available to authorized users.
When an AI agent discovers available tools through the proxy, it only receives information about tools that have been approved for the current user. When the agent calls the new tool, the proxy routes the request to the tool only if the user is authorized to access it.
This workflow ensures that new tools undergo proper vetting and approval before they can be used, and that access is restricted to authorized users only. It also centralizes the tool governance process, making it easier to manage the lifecycle of MCP tools in a secure manner.
By recognizing these challenges, security engineers and architects can design defenses before problems occur. We next look at how an identity-aware proxy can provide those defenses in a clean, centralized way.
A proven design in cloud architectures is to put a reverse proxy (often called an API gateway) in front of your services. MCP-based AI systems are no exception. By introducing an intelligent proxy between AI agents (clients) and the MCP servers (tools/backends), we create a controlled funnel through which all AI tool traffic passes. This proxy can operate at Layer 7 (application layer), meaning it understands HTTP and even JSON payloads, allowing fine-grained control. Below, we outline the key roles such a proxy plays in securing MCP:
graph TB
subgraph "Client Side"
User[User]
AIAgent[AI Agent]
User -->|interacts| AIAgent
end
subgraph "Security Layer"
Proxy[API Gateway/Proxy]
Auth[Authentication]
RBAC[Authorization/RBAC]
Registry[Tool Registry]
Audit[Audit Logging]
Proxy -->|uses| Auth
Proxy -->|enforces| RBAC
Proxy -->|consults| Registry
Proxy -->|generates| Audit
end
subgraph "MCP Tools"
Tool1[Document Search]
Tool2[Database Query]
Tool3[File Operations]
Tool4[External API]
end
subgraph "Backend Systems"
DB[(Databases)]
Storage[File Storage]
APIs[Internal APIs]
External[External Services]
end
AIAgent -->|MCP requests| Proxy
Proxy -->|routes to| Tool1
Proxy -->|routes to| Tool2
Proxy -->|routes to| Tool3
Proxy -->|routes to| Tool4
Tool1 -->|reads| DB
Tool1 -->|reads| Storage
Tool2 -->|queries| DB
Tool3 -->|manages| Storage
Tool4 -->|calls| APIs
Tool4 -->|calls| External
classDef security fill:#f96,stroke:#333,stroke-width:2px;
class Proxy,Auth,RBAC,Registry,Audit security;
This diagram provides a detailed view of the identity-aware proxy pattern for MCP. The architecture is divided into four main layers:
All MCP requests from AI agents must pass through the proxy, which authenticates the requests, enforces RBAC policies, consults the tool registry to determine routing, and generates audit logs. The proxy then routes authorized requests to the appropriate MCP tools, which in turn interact with the backend systems.
This centralized security architecture ensures consistent enforcement of security policies across all MCP interactions, regardless of which tools are being used or which backend systems are being accessed.
Unlike a simple stateless API call, MCP sessions can be long-lived and involve streaming (Server-Sent Events for output, etc.). The proxy should ensure that all requests and responses belonging to a given session or conversation are handled consistently. This often means implementing session affinity – if multiple instances of an MCP server are running, the proxy will route a given session’s traffic to the same instance each time. This prevents issues where, say, tool A’s state (in-memory cache, context window, etc.) is lost because request 2 went to a different instance than request 1. Modern proxies can do session-aware load balancing using HTTP headers or routes (for example, mapping a session ID or client ID in the URL to a particular backend). Additionally, the proxy can handle SSE connections gracefully, so that streaming responses aren’t accidentally broken by network intermediaries. Should a session need to be resumed or handed off, the gateway can coordinate that (as proposed in upcoming Envoy features for MCP). In short, the proxy ensures reliability and consistency for MCP’s stateful interactions, which is crucial for user experience and for maintaining correct context.
sequenceDiagram
participant User
participant AIAgent as AI Agent
participant Proxy as API Gateway
participant Instance1 as Tool Instance 1
participant Instance2 as Tool Instance 2
User->>AIAgent: Start conversation
AIAgent->>Proxy: MCP request 1 (session=abc123)
Note over Proxy: Session affinity routing
Proxy->>Instance1: Route to instance 1
Instance1->>Proxy: Response with state
Proxy->>AIAgent: Return response
User->>AIAgent: Continue conversation
AIAgent->>Proxy: MCP request 2 (session=abc123)
Note over Proxy: Same session ID routes to same instance
Proxy->>Instance1: Route to instance 1 (preserves state)
Instance1->>Proxy: Response with updated state
Proxy->>AIAgent: Return response
Note over User,Instance2: Without session affinity, request might go to instance 2 and lose state
This sequence diagram illustrates how session affinity works in an MCP environment. When a user starts a conversation with an AI agent, the agent makes an MCP request to the API Gateway with a session identifier (in this case, “abc123”). The gateway uses this session ID to route the request to a specific tool instance (Instance 1).
When the user continues the conversation, the agent makes another MCP request with the same session ID. Because the gateway implements session affinity, it routes this request to the same instance (Instance 1), which preserves the state from the previous interaction. This ensures a consistent and coherent experience for the user.
Without session affinity, the second request might be routed to a different instance (Instance 2), which would not have the state information from the first request. This would result in a broken experience, as the tool would not have the context of the previous interaction.
Session affinity is particularly important for MCP because many AI interactions are stateful and context-dependent. The proxy’s ability to maintain this session consistency is a key advantage over simpler API integration approaches.
Every request hitting the MCP gateway should carry a valid identity token – typically a JSON Web Token (JWT) issued by an Identity Provider via OIDC (OpenID Connect). By requiring JWTs, the proxy offloads authentication from the tools themselves and ensures that only authenticated, authorized calls make it through. In practice, this means the AI agent (or the user’s session with the agent) must obtain an OIDC token (for example, an ID token or access token) and attach it to each MCP request (often in an HTTP header like Authorization: Bearer <token>). The proxy verifies this token, checks signature and claims (issuer, audience, expiration, etc.), and rejects any request that isn’t properly authenticated. This way, your MCP servers never see an anonymous call – they trust the gateway to have vetted identity.
sequenceDiagram
participant User
participant App as AI Application
participant IdP as Identity Provider
participant Proxy as API Gateway
participant Tool as MCP Tool
User->>App: Access AI application
App->>IdP: Redirect to login
User->>IdP: Authenticate
IdP->>App: Authorization code
App->>IdP: Exchange code for tokens
IdP->>App: ID token + access token
Note over App: Store tokens securely
User->>App: Request using AI tool
App->>Proxy: MCP request with access token
Proxy->>Proxy: Validate token (signature, expiry, audience)
Proxy->>Proxy: Extract user identity and permissions
alt Token Valid
Proxy->>Tool: Forward request with user context
Tool->>Proxy: Response
Proxy->>App: Return response
App->>User: Display result
else Token Invalid
Proxy->>App: 401 Unauthorized
App->>User: Session expired, please login again
end
Note over App,Proxy: Token refresh happens in background
App->>IdP: Refresh token when needed
IdP->>App: New access token
This sequence diagram illustrates the OIDC authentication flow in an MCP environment. The process begins when a user accesses the AI application, which redirects to the Identity Provider for authentication. After the user authenticates, the Identity Provider issues an authorization code, which the application exchanges for ID and access tokens.
The application securely stores these tokens and uses the access token when making MCP requests through the AI agent. When the proxy receives a request, it validates the token by checking the signature, expiration, audience, and other claims. It also extracts the user’s identity and permissions from the token.
If the token is valid, the proxy forwards the request to the appropriate MCP tool along with the user’s context. The tool processes the request and returns a response, which flows back through the proxy to the application and ultimately to the user.
If the token is invalid (expired, tampered with, etc.), the proxy returns a 401 Unauthorized response, and the application prompts the user to log in again.
In the background, the application can use a refresh token to obtain new access tokens when needed, without requiring the user to re-authenticate. This ensures a smooth user experience while maintaining security.
This OIDC integration provides a robust authentication mechanism that is widely adopted in enterprise environments and integrates well with existing identity management systems.
While the discussion above focuses on authenticating the human user, a production-grade MCP deployment must also identify two additional actors:
Our companion post “OpenID Connect for Agents (OIDC-A) 1.0 Proposal” (/2025/04/28/oidc-a-proposal/) extends OIDC Core 1.0 with a rich set of claims for agent identity, attestation, and delegation chains. In practice this means:
agent_type, agent_model, agent_instance_id, delegator_sub, delegation_chain, etc.). This token travels alongside the user’s access token in every MCP request.agent_capabilities, agent_trust_level, agent_attestation).Adopting OIDC-A brings several benefits:
email:draft capability to invoke the Mail tool).agent_attestation) enables the gateway to verify the integrity and provenance of both agents and tools before routing traffic to them.For the remainder of this article, whenever we refer to a “token” being validated by the gateway, assume this now encompasses the user’s token, the agent’s OIDC-A token, and (optionally) the tool/resource token – all evaluated in a single policy decision step.
This pattern is already used widely in API security: “an API Gateway can securely and consistently implement authentication… without burdening the applications themselves.” In our context, the MCP proxy might integrate with your enterprise SSO (Azure AD, Okta, etc.) via OIDC to handle user login flows and token validation. Many gateways support OIDC natively, initiating redirects for user login if needed and then storing the resulting token in a cookie for session continuity. In a headless agent scenario (where the AI is calling tools server-to-server), the token might be provisioned out-of-band (e.g. the user logged into the AI app, so the app injects the token for the agent to use). Either way, the gateway enforces that no token = no access. It can also map token claims to roles or scopes to implement authorization (e.g., only users with an “HR_read” scope can use the “HR Database” tool). This aligns perfectly with MCP’s design goal of secure connections – combining MCP with OIDC and OIDC-A gives you an end-to-end authenticated channel for tool usage.
sequenceDiagram
participant User
participant Agent as LLM Agent (OIDC-A)
participant Proxy as API Gateway
participant Tool as MCP Tool (OIDC-A)
participant Backend as Backend System
User->>Agent: 1. Interact (chat, form, etc.)
Agent->>Proxy: 2. MCP request\nBearer user token + agent OIDC-A token
Proxy->>Proxy: 3. Validate user token (OIDC) & agent token (OIDC-A)
Proxy-->>Tool: 4. Forward request plus optional *resource token* for the tool
Tool->>Backend: 5. Query/act using delegated auth
Backend-->>Tool: 6. Data / result
Tool-->>Proxy: 7. Response (may include attestation)
Proxy-->>Agent: 8. Authorized response
Agent-->>User: 9. Present result
A powerful advantage of the proxy is that it can make routing decisions based not just on URLs, but on metadata within the requests. With MCP, requests and responses are in JSON-RPC format, which includes fields like the tool method name, parameters, and even tool annotations. An identity-aware proxy can be configured to inspect these details and apply policy rules. For example, you might configure rules such as:
graph TD
subgraph "MCP Request"
Request[JSON-RPC Request]
Method[Tool Method]
Params[Parameters]
User[User Identity]
end
subgraph "Policy Engine"
Rules[Policy Rules]
RBAC[Role-Based Access]
Audit[Audit Logging]
Transform[Response Transformation]
end
Request --> Method
Request --> Params
Request --> User
Method --> Rules
Params --> Rules
User --> RBAC
Rules --> Decision{Allow/Deny}
RBAC --> Decision
Decision -->|Allow| Forward[Forward to Tool]
Decision -->|Deny| Reject[Reject Request]
Forward --> Audit
Reject --> Audit
Forward --> Tool[MCP Tool]
Tool --> Response[Tool Response]
Response --> Transform
Transform --> Filtered[Filtered Response]
classDef request fill:#bbf,stroke:#333,stroke-width:1px;
classDef policy fill:#fbf,stroke:#333,stroke-width:1px;
classDef action fill:#bfb,stroke:#333,stroke-width:1px;
class Request,Method,Params,User request;
class Rules,RBAC,Audit,Transform policy;
class Decision,Forward,Reject,Filtered action;
This diagram illustrates how tool metadata filtering and policy enforcement work in an MCP proxy. The process begins with an MCP request in JSON-RPC format, which contains the tool method, parameters, and user identity information. These components are extracted and fed into the policy engine.
The policy engine consists of policy rules, role-based access control (RBAC), audit logging, and response transformation components. The tool method and parameters are evaluated against the policy rules, while the user identity is checked against RBAC permissions.
Based on these evaluations, the policy engine makes an allow/deny decision. If the request is allowed, it is forwarded to the MCP tool; if denied, it is rejected. In either case, the action is logged for audit purposes.
When a request is allowed and processed by the tool, the response may pass through a transformation step before being returned to the client. This transformation can filter or modify the response based on security policies, such as removing sensitive information that the user shouldn’t see.
This fine-grained policy enforcement at the metadata level allows for sophisticated security controls that go far beyond simple URL-based routing. For example:
delete_file and the user is not in the IT Admin group, deny the request.”execute_sql tool on weekdays between 9am-5pm, and log all queries.”This is analogous to a web application firewall (WAF) or an API gateway performing content filtering, but tailored to AI tool usage. In the Envoy MCP proposal, this corresponds to parsing MCP messages and using RBAC filters on them. The proxy essentially understands the intent of each tool call and can gate it appropriately. It also can redact or transform data if needed – for instance, stripping out certain fields from a response that the user shouldn’t see, or masking personally identifiable information. By centralizing this in the gateway, you avoid having to implement checks in each tool service (which could be inconsistent or forgotten). Auditing is another benefit: the proxy can log every tool invocation along with user identity and parameters, feeding into SIEM systems for monitoring. That way, if an AI one day does something it shouldn’t, you have a clear trail of which tool call was involved and who prompted it. In sum, metadata-based filtering turns the proxy into a smart policy enforcement point, adding a safety layer on top of MCP’s basic capabilities.
Enterprises constantly evolve their services – new versions, A/B tests, staging vs. production deployments, etc. The proxy can greatly simplify how AI agents handle these changes. Instead of the AI needing to know which version of a tool to call, the gateway can implement version-aware routing. For instance, the MCP endpoint for a “Document Search” tool could remain the same for the agent, but the proxy might route 90% of requests to v1 of the service and 10% to a new v2 (for a canary rollout). Or route internal users to a “beta” instance while external users go to stable. This is done by matching on request attributes or using routing rules that include user audience and tool identifiers.
graph TB
AIAgent[AI Agent] -->|MCP Request| Proxy[API Gateway]
Proxy -->|"90% traffic"| V1[Tool v1]
Proxy -->|"10% traffic"| V2[Tool v2 - Canary]
Proxy -->|"Internal Users"| Beta[Beta Version]
Proxy -->|"External Users"| Stable[Stable Version]
Proxy -->|"Small Requests"| Standard[Standard Instance]
Proxy -->|"Large Requests"| HighMem[High-Memory Instance]
Proxy -->|"US Users"| US[US Region]
Proxy -->|"EU Users"| EU[EU Region]
classDef proxy fill:#f96,stroke:#333,stroke-width:2px;
classDef version fill:#bbf,stroke:#333,stroke-width:1px;
classDef audience fill:#bfb,stroke:#333,stroke-width:1px;
classDef size fill:#fbf,stroke:#333,stroke-width:1px;
classDef region fill:#ff9,stroke:#333,stroke-width:1px;
class Proxy proxy;
class V1,V2 version;
class Beta,Stable audience;
class Standard,HighMem size;
class US,EU region;
This diagram illustrates the various routing strategies that an API Gateway can implement for MCP requests. The gateway can route traffic based on multiple factors:
Version-based routing: The gateway can split traffic between different versions of a tool, such as sending 90% to v1 and 10% to a canary deployment of v2. This allows for gradual rollouts and A/B testing without requiring changes to the AI agents.
Audience-based routing: Internal users can be directed to beta versions of tools, while external users are routed to stable versions. This allows for internal testing and validation before wider release.
Request size-based routing: Small requests can be handled by standard instances, while large requests that require more resources are directed to high-memory instances. This optimizes resource utilization and ensures that demanding requests don’t impact the performance of standard operations.
Geographic routing: Users from different regions can be directed to region-specific instances, reducing latency and potentially addressing data residency requirements.
The AI agent doesn’t need to be aware of these routing decisions; it simply makes requests to the logical tool name, and the gateway handles the complexity of routing to the appropriate backend. This abstraction simplifies the agent’s implementation while providing powerful operational capabilities.
Similarly, routing can consider context – e.g., direct requests to the nearest regional server for lower latency if the user’s location is known, or choose a different backend depending on the size of the request (perhaps a special high-memory instance for very large files). All of this is configurable at the proxy level. The AI agent simply calls the logical tool name, and the gateway takes care of finding the right backend. This not only eases operations (you can upgrade backend tools without breaking the AI’s interface), but also adds to security. You could isolate certain versions for testing, or ensure that experimental tools are only accessible under certain conditions. By controlling traffic flow, the proxy helps maintain a principle of least privilege on a macro scale – the AI only reaches the backends it’s supposed to, via routes that are appropriate for the current context.
Now that we’ve covered the key security patterns, let’s look at a practical approach to implementing MCP security with an identity-aware proxy. This section outlines the steps to set up a secure MCP environment, focusing on the integration points between components.
graph TB
subgraph ImplementationSteps["Implementation Steps"]
Step1[1. Set up Identity Provider]
Step2[2. Configure API Gateway]
Step3[3. Implement Tool Registry]
Step4[4. Define Security Policies]
Step5[5. Integrate AI Agents]
Step6[6. Monitor and Audit]
Step1 --> Step2
Step2 --> Step3
Step3 --> Step4
Step4 --> Step5
Step5 --> Step6
end
classDef step fill:#beb,stroke:#333,stroke-width:1px
class Step1,Step2,Step3,Step4,Step5,Step6 step
This diagram outlines the six key steps in implementing MCP security with a proxy. The process follows a logical progression:
Each step builds on the previous ones, creating a comprehensive security implementation. The following sections will explore each step in detail.
The first step is to configure your identity provider (IdP) to support the OIDC flows needed for MCP security. This typically involves:
The IdP will be responsible for authenticating users and issuing the tokens that will be used to secure MCP requests. It’s important to configure the appropriate scopes and claims to ensure that the tokens contain the necessary information for authorization decisions.
Next, you’ll need to configure your API gateway to act as the MCP proxy. This involves:
sequenceDiagram
participant Admin
participant Gateway as API Gateway
participant IdP as Identity Provider
Admin->>Gateway: 1. Configure OIDC integration
Gateway->>IdP: 2. Fetch OIDC discovery document
IdP->>Gateway: 3. Return endpoints and keys
Admin->>Gateway: 4. Set up MCP routing rules
Admin->>Gateway: 5. Configure security policies
Note over Gateway: Gateway ready to validate tokens and route MCP traffic
This sequence diagram illustrates the process of configuring an API Gateway for MCP security. The process begins with an administrator configuring the OIDC integration in the gateway. The gateway then fetches the OIDC discovery document from the Identity Provider, which returns the necessary endpoints and keys for token validation.
Next, the administrator sets up MCP routing rules, defining how requests should be directed to different MCP tools based on various criteria. The administrator also configures security policies, specifying who can access which tools and under what conditions.
Once these configurations are complete, the gateway is ready to validate tokens and route MCP traffic according to the defined rules and policies. This setup process establishes the gateway as the central security control point for all MCP interactions.
The configuration steps include:
The gateway will be responsible for validating the tokens, enforcing the security policies, and routing the MCP requests to the appropriate backends. It’s important to ensure that the gateway is properly configured to handle the MCP JSON-RPC format and to extract the necessary information for policy decisions.
A tool registry is essential for managing the lifecycle of MCP tools in your environment. This involves:
The tool registry will be responsible for maintaining the list of available tools, their endpoints, and their access requirements. It will also provide the necessary information to the API gateway for routing and policy enforcement.
graph TB
subgraph "Tool Registry"
DB[(Tool Database)]
API[Registry API]
UI[Admin UI]
UI -->|Manage Tools| API
API -->|CRUD Operations| DB
end
subgraph "Integration Points"
Gateway[API Gateway]
Agents[AI Agents]
API -->|Tool Configurations| Gateway
API -->|Available Tools| Agents
end
subgraph "Tool Lifecycle"
Register[Register]
Approve[Approve]
Deploy[Deploy]
Monitor[Monitor]
Retire[Retire]
Register --> Approve
Approve --> Deploy
Deploy --> Monitor
Monitor --> Retire
end
classDef registry fill:#bbf,stroke:#333,stroke-width:1px;
classDef integration fill:#fbf,stroke:#333,stroke-width:1px;
classDef lifecycle fill:#bfb,stroke:#333,stroke-width:1px;
class DB,API,UI registry;
class Gateway,Agents integration;
class Register,Approve,Deploy,Monitor,Retire lifecycle;
This diagram illustrates the components and lifecycle of a Tool Registry in an MCP environment. The Tool Registry consists of three main components:
The Tool Registry integrates with two key systems:
The diagram also shows the lifecycle of an MCP tool:
This comprehensive approach to tool management ensures that all MCP tools are properly vetted, deployed, and monitored throughout their lifecycle, reducing security risks and operational issues.
Security policies are the rules that govern access to MCP tools. This involves:
The security policies will be enforced by the API gateway based on the user’s identity and the tool being accessed. It’s important to ensure that the policies are comprehensive and aligned with your organization’s security requirements.
Finally, you’ll need to integrate your AI agents with the secure MCP environment. This involves:
The AI agents will be responsible for obtaining the necessary tokens and including them in MCP requests. They’ll also need to handle authentication and authorization errors gracefully, providing appropriate feedback to users.
sequenceDiagram
participant User
participant Agent as AI Agent
participant App as Application
participant IdP as Identity Provider
participant Gateway as API Gateway
participant Tool as MCP Tool
User->>App: Access AI application
App->>IdP: Authenticate user
IdP->>App: Issue tokens
User->>Agent: Request using AI capabilities
Agent->>App: Request token for MCP
App->>Agent: Provide token
Agent->>Gateway: MCP request with token
Gateway->>Gateway: Validate token & apply policies
Gateway->>Tool: Forward authorized request
Tool->>Gateway: Response
Gateway->>Agent: Return response
Agent->>User: Present result
Note over App,Gateway: Token refresh cycle
App->>IdP: Refresh token when needed
IdP->>App: New access token
This sequence diagram illustrates the integration of AI agents with a secure MCP environment. The process begins when a user accesses the AI application, which authenticates the user with the Identity Provider and receives tokens.
When the user makes a request that requires AI capabilities, the AI agent requests a token from the application, which provides it. The agent then includes this token in its MCP request to the API Gateway.
The gateway validates the token and applies security policies to determine if the request should be allowed. If authorized, the request is forwarded to the appropriate MCP tool, which processes it and returns a response. This response flows back through the gateway to the agent and ultimately to the user.
In the background, the application handles token refresh cycles, requesting new access tokens from the Identity Provider when needed. This ensures continuous operation without requiring the user to re-authenticate frequently.
This integration approach ensures that AI agents operate within the security framework established by the proxy architecture, with all requests properly authenticated and authorized.
By implementing a secure MCP architecture with an identity-aware proxy, you move far beyond “glorified API calls” to a robust, enterprise-grade integration between AI agents and your business systems. This approach addresses the key security challenges of MCP deployments, including:
The proxy-based architecture provides a centralized control point for enforcing security policies, managing tool access, and monitoring AI agent activity. It also simplifies operations by abstracting away the complexity of backend services and providing a consistent interface for AI agents.
As MCP continues to evolve and gain adoption, the security patterns described in this article will become increasingly important for enterprise deployments. By implementing these patterns now, you can ensure that your AI agent infrastructure is secure, scalable, and ready for the future.
graph LR
A[Glorified API Calls] -->|Evolution| B[Secure MCP Architecture]
subgraph "Key Benefits"
C[Centralized Security]
D[Identity Propagation]
E[Policy Enforcement]
F[Audit & Compliance]
G[Operational Simplicity]
end
B --> C
B --> D
B --> E
B --> F
B --> G
classDef benefit fill:#bfb,stroke:#333,stroke-width:1px;
class C,D,E,F,G benefit;
This final diagram summarizes the evolution from “glorified API calls” to a secure MCP architecture, highlighting the key benefits of this approach:
By adopting this architecture, organizations can confidently deploy AI agents in enterprise environments, knowing that their MCP interactions are secure, auditable, and manageable at scale. This represents a significant advancement beyond the simplistic view of AI tools as mere API calls, recognizing the complex security requirements of production AI systems.
--- ## OpenID Connect for Agents (OIDC-A) 1.0 Proposal URL: https://subramanya.ai/2025/04/28/oidc-a-proposal/ Date: 2025-04-28 Tags: OpenID, OAuth, AI, Agents, Security, Identity, Authentication, Authorization, Standards, Proposal, SpecificationThis document proposes a standard extension to OpenID Connect for representing and verifying the identity of LLM-based agents. It integrates the core proposal with detailed frameworks for verification, attestation, and delegation chains.
OpenID Connect for Agents (OIDC-A) 1.0 is an extension to OpenID Connect Core 1.0 that provides a framework for representing, authenticating, and authorizing LLM-based agents within the OAuth 2.0 ecosystem. This specification defines standard claims, endpoints, and protocols for establishing agent identity, verifying agent attestation, representing delegation chains, and enabling fine-grained authorization based on agent attributes.
As LLM-based agents become increasingly prevalent in digital ecosystems, there is a growing need for standardized methods to represent their identity and manage their authorization. Traditional OAuth 2.0 and OpenID Connect protocols were designed primarily for human users and conventional applications, lacking the necessary constructs to represent the unique characteristics of autonomous agents, such as:
This specification addresses these gaps by extending OpenID Connect to provide a comprehensive framework for agent identity and authorization.
This specification uses the terms defined in OAuth 2.0 [RFC6749], OpenID Connect Core 1.0, and the following additional terms:
OIDC-A extends OpenID Connect by:
The following claims MUST or SHOULD be included in ID Tokens issued to or about agents:
| Claim | Type | Description | Requirement |
|---|---|---|---|
agent_type |
string | Identifies the type/class of agent (e.g., "assistant", "retrieval", "coding") | REQUIRED |
agent_model |
string | Identifies the specific model (e.g., "gpt-4", "claude-3-opus", "gemini-pro") | REQUIRED |
agent_version |
string | Version identifier of the agent model | RECOMMENDED |
agent_provider |
string | Organization that provides/hosts the agent (e.g., "openai.com", "anthropic.com") | REQUIRED |
agent_instance_id |
string | Unique identifier for this specific instance of the agent | REQUIRED |
| Claim | Type | Description | Requirement |
|---|---|---|---|
delegator_sub |
string | Subject identifier of the entity who most recently delegated authority to this agent | REQUIRED |
delegation_chain |
array | Ordered array of delegation steps (see Section 2.4.2) | OPTIONAL |
delegation_purpose |
string | Description of the purpose/intent for which authority was delegated | RECOMMENDED |
delegation_constraints |
object | Constraints placed on the agent by the delegator | OPTIONAL |
| Claim | Type | Description | Requirement |
|---|---|---|---|
agent_capabilities |
array | Array of capability identifiers representing what the agent can do | RECOMMENDED |
agent_trust_level |
string | Trust classification of the agent (e.g., "verified", "experimental") | OPTIONAL |
agent_attestation |
object | Attestation evidence or reference (see Section 2.4.4) | RECOMMENDED |
agent_context_id |
string | Identifier for the conversation/task context | RECOMMENDED |
agent_typeString value from a defined set of agent types. Implementers SHOULD use one of the following values when applicable:
assistant: General-purpose assistant agentretrieval: Agent specialized in information retrievalcoding: Agent specialized in code generation or analysisdomain_specific: Agent specialized for a particular domainautonomous: Agent with high degree of autonomysupervised: Agent requiring human supervision for key actionsCustom types MAY be used but SHOULD follow the format vendor:type (e.g., acme:financial_advisor).
delegation_chainJSON array containing objects representing each step in the delegation chain, from the original user to the current agent. Each object MUST contain:
iss: REQUIRED. String identifying the Authorization Server or entity that issued/validated this delegation step.sub: REQUIRED. String identifying the delegator (the entity granting permission).aud: REQUIRED. String identifying the delegatee (the agent receiving permission).delegated_at: REQUIRED. NumericDate representing the time the delegation occurred.scope: REQUIRED. Space-separated string of OAuth scopes representing the permissions granted in this delegation step. MUST be a subset of the scopes held by the delegator (sub).purpose: OPTIONAL. String describing the intended purpose of this delegation step.constraints: OPTIONAL. JSON object specifying constraints on the delegation (e.g., {"max_duration": 3600, "allowed_resources": ["/data/abc"]}).jti: OPTIONAL. A unique identifier for this specific delegation step, useful for revocation or tracking.The array MUST be ordered chronologically.
Validation Rules for delegation_chain (performed by Relying Party):
delegated_at.iss is trusted.aud of step N matches sub of step N+1.scope in each step is a subset of/equal to the delegator’s available scopes.constraints.agent_capabilitiesArray of string identifiers representing the agent’s capabilities. Implementers SHOULD use capability identifiers from a well-defined taxonomy when available. Custom capabilities SHOULD follow the format vendor:capability (e.g., acme:financial_analysis).
agent_attestationJSON object containing attestation evidence or a reference to it. MUST include a format field indicating the type of evidence.
Recommended Format: JWT-based, potentially compatible with IETF RATS Entity Attestation Token (EAT).
Example:
"agent_attestation": {
"format": "urn:ietf:params:oauth:token-type:eat",
"token": "eyJhbGciOiJFUzI1NiIsInR5cCI6ImVhdCtqd3QifQ..."
}
Other formats (e.g., "format": "TPM2-Quote", "format": "SGX-Quote") MAY be used.
The OIDC-A authentication flow extends the standard OpenID Connect Authentication flow:
agent scope and potentially delegation_context.When an agent is delegated authority:
delegator_sub, delegation_chain (updated), delegation_purpose, and constrained scope.To verify an agent’s attestation:
agent_attestation claim in its ID Token or provides evidence separately.format:
agent_attestation_endpoint for validation assistance.verified: true/false).Extends OAuth 2.0 Dynamic Client Registration [RFC7591]:
| Parameter | Type | Description |
|---|---|---|
agent_provider |
string | Identifier of the agent provider |
agent_models_supported |
array | List of supported agent models |
agent_capabilities |
array | List of agent capabilities |
attestation_formats_supported |
array | List of supported attestation formats |
delegation_methods_supported |
array | List of supported delegation methods |
Extends OpenID Connect Discovery 1.0:
| Parameter | Type | Description |
|---|---|---|
agent_attestation_endpoint |
string | URL of the attestation endpoint |
agent_capabilities_endpoint |
string | URL of the capabilities discovery endpoint |
agent_claims_supported |
array | List of supported agent claims |
agent_types_supported |
array | List of supported agent types |
delegation_methods_supported |
array | List of supported delegation methods |
attestation_formats_supported |
array | List of supported attestation formats |
attestation_verification_keys_endpoint |
string | URL to retrieve public keys for verifying attestation signatures |
An OAuth 2.0 protected resource that returns attestation information about an agent or assists in validating provided evidence. URL advertised via agent_attestation_endpoint discovery parameter.
GET /agent/attestation?agent_id=123&nonce=abc
Authorization: Bearer <token>
{
"verified": true,
"provider": "openai.com",
"model": "gpt-4",
"version": "2025-03",
"attestation_timestamp": 1714348800,
"attestation_signature": "..."
}
Provides information about an agent’s capabilities. URL advertised via agent_capabilities_endpoint discovery parameter.
GET /.well-known/agent-capabilities
{
"capabilities": [
{"id": "text_generation", "description": "..."},
{"id": "code_generation", "description": "..."}
],
"supported_constraints": ["max_tokens", "allowed_tools"]
}
Agents SHOULD use strong, asymmetric methods (JWT Client Auth [RFC7523], mTLS [RFC8705]), potentially combined with attestation. Shared secrets are NOT RECOMMENDED.
Systems MUST validate the entire delegation chain, enforce scope reduction, implement consent mechanisms, and consider time-bounding. Policies may limit chain length. Robust revocation mechanisms are needed.
Requires secure management of signing keys, robust nonce handling, trustworthy known-good measurements, secure endpoints, and protection against replay attacks. Attestation evidence may have privacy implications.
ID Tokens with agent claims SHOULD be encrypted. Access tokens SHOULD have limited lifetimes. Refresh tokens for agents require careful consideration.
Implementations MUST consider potential correlation of agent identity, privacy implications of delegation chains, user consent requirements, and data minimization in claims.
OIDC-A 1.0 is designed for compatibility with OAuth 2.0 [RFC6749], OIDC Core 1.0, JWT [RFC7519], and related RFCs. Future versions will aim for backward compatibility.
{
"iss": "https://auth.example.com",
"sub": "agent_instance_789",
"aud": "client_123",
"exp": 1714435200,
"iat": 1714348800,
"auth_time": 1714348800,
"nonce": "n-0S6_WzA2Mj",
"agent_type": "assistant",
"agent_model": "gpt-4",
"agent_version": "2025-03",
"agent_provider": "openai.com",
"agent_instance_id": "agent_instance_789",
"delegator_sub": "user_456",
"delegation_purpose": "Email management assistant",
"agent_capabilities": ["email:read", "email:draft", "calendar:view"],
"agent_trust_level": "verified",
"agent_context_id": "conversation_123",
"agent_attestation": {
"format": "urn:ietf:params:oauth:token-type:eat",
"token": "eyJhbGciOiJSUzI1NiIsInR5cCI6IkpXVCJ9...",
"timestamp": 1714348800
},
"delegation_chain": [
{
"iss": "https://auth.example.com",
"sub": "user_456",
"aud": "agent_instance_789",
"delegated_at": 1714348700,
"scope": "email profile calendar"
}
]
}
"delegation_chain": [
{
"iss": "https://auth.example.com",
"sub": "user_456",
"aud": "agent_instance_789",
"delegated_at": 1714348800,
"scope": "email calendar",
"purpose": "Manage my emails and calendar"
},
{
"iss": "https://auth.example.com",
"sub": "agent_instance_789",
"aud": "agent_instance_101",
"delegated_at": 1714348830,
"scope": "calendar:view",
"purpose": "Analyze available time slots"
}
]
Traditional automation tools like Robotic Process Automation (RPA) and Integration Platform as a Service (iPaaS) have long served as the backbone of enterprise workflows. These systems, designed to automate repetitive tasks and connect disparate software tools, have delivered undeniable value. However, their inherent limitations are becoming increasingly evident. They require significant manual setup, often break when systems change, and struggle to handle unstructured data such as documents, emails, or images.
Enter AI agents — a revolutionary leap from static, rule-based automation to intelligent, adaptable systems. AI agents promise to overcome the constraints of traditional tools, paving the way for smarter, more efficient enterprise automation. An excellent breakdown of their significance can be found in the insightful Menlo Ventures article “Beyond Bots: How AI Agents Are Driving the Next Wave of Enterprise Automation”.
AI agents represent a fundamental paradigm shift. Unlike their predecessors, these systems are not bound by rigid rules or pre-defined workflows. Instead, they possess the ability to learn, adapt, and make decisions based on changing circumstances. This adaptability enables them to address dynamic and complex tasks, unlocking unprecedented levels of efficiency and scalability.
However, this evolution introduces a new layer of complexity: agentic security. As AI agents grow more autonomous, ensuring their security, transparency, and trustworthiness becomes paramount, particularly in multi-agent environments where multiple AI systems must collaborate. This shift necessitates rethinking how we secure enterprise automation systems to ensure they remain robust and trustworthy in a rapidly evolving landscape.
Agentic security involves safeguarding intelligent, autonomous systems while maintaining their transparency and reliability. It becomes especially critical in environments where multiple AI agents operate simultaneously, managing dynamic processes and sensitive data. Key considerations for agentic security include:
AI agents excel at adjusting to system changes, but their adaptability must not come at the expense of enterprise security. In multi-agent environments, secure communication protocols and strong authentication mechanisms form the foundation of security. However, static security measures alone are insufficient. Evolving contexts require context-aware security — a system that dynamically adjusts access controls and agent behavior based on situational needs and data sensitivities. This mitigates risks such as unauthorized escalations, prompt injection attacks, and data breaches.
For example, a financial reporting agent, which has access to internal financial metrics, should be able to generate a detailed report for C-suite agents while maintaining strict data boundaries. If an HR agent requests information about salaries, the financial agent should only provide relevant, pre-approved metrics, such as aggregated departmental budgets, rather than individual salary slips. This ensures that agents respect organizational boundaries and adhere to context-aware security protocols.
In cross-enterprise collaborations, where AI agents from different organizations interact, maintaining the integrity of each participant’s systems is essential. Context-aware security ensures that agents respect boundaries and operate within predefined limits, even as they adapt to new information or changing environments.
As AI agents take on more critical roles in enterprise processes, transparency and accountability become non-negotiable. Organizations must implement mechanisms to trace and audit agent decisions, ensuring they align with business objectives and ethical standards. This is particularly important in regulated industries, where compliance requirements demand a clear understanding of how and why decisions are made.
In scenarios where multiple agents collaborate, trust is the cornerstone of effective operation. Agents must communicate securely, share information responsibly, and resolve conflicts without compromising the integrity of the broader system. Establishing trust requires robust encryption, tamper-proof logs, and mechanisms for conflict resolution to prevent unintended behaviors or system failures.
AI agents represent the next frontier in enterprise automation, promising smarter, faster, and more scalable workflows. However, their increasing sophistication demands a proactive approach to agentic security. As organizations embrace these intelligent systems, they must prioritize building trust, safeguarding data, and ensuring transparency to foster sustainable innovation.
The Menlo Ventures article encapsulates this beautifully: AI agents are not just tools — they are collaborators, reshaping how enterprises operate. But with great power comes great responsibility. By addressing the challenges of agentic security, we can unlock the full potential of AI agents while preserving the integrity and trust that underpin modern enterprises.
--- ## A feat of strength MVP for AI Apps URL: https://subramanya.ai/2024/02/20/a-feat-of-strength-mvp-for-ai-apps/ Date: 2024-02-20 Tags: AI, MVP, Product Development, User Feedback, InnovationA minimum viable product (MVP) is a version of a product with just enough features to be usable by early customers, who can then provide feedback for future product development.
Today I want to focus on what that looks like for shipping AI applications. To do that, we only need to understand 4 things.
The Pareto principle, also known as the 80/20 rule, still applies but in a different way than you might think.
An analogy I often use to help understand this concept is as follows: You need something to help get from point A to point B. Maybe the vision is to have a car. However, the MVP is not a chassis without wheels or an engine. Instead, it might look like a skateboard. You’ll ship and realize the product needs brakes or steering. So then you ship a scooter. Afterwards, you figure out the scooter needs more leverage, so you add larger wheels and end up with a bicycle. Limited by the force you can apply as a human being, you start thinking about motors and can branch out into mopeds, e-bikes, and motorcycles. Then one day, ship the car.
When talking about something being 80% done or 80% ready, it is usually in a machine-learning sense. In this context, each component is deterministic, which means 80% translates to 8 out of 10 features being complete. Once the remaining 2 features are ready, we can ship the product. However, If we want to follow the 80/20 rule, we might be able to ship the product with 80% of the features and then add the remaining 20% later, like a car without a radio or air conditioning. However, The meaning of 80% can vary significantly, and this definition may not apply to an AI-powered application.
The issue with Summary Statistics
 The above image is an example of Anscombe’s quartet. It’s a set of four datasets that have nearly identical simple descriptive statistics yet very different distributions and appearances. This is a classic explanation of why summary statistics can be misleading.
The above image is an example of Anscombe’s quartet. It’s a set of four datasets that have nearly identical simple descriptive statistics yet very different distributions and appearances. This is a classic explanation of why summary statistics can be misleading.
Consider the following example:
| Query_id | score |
|---|---|
| 1 | 0.9 |
| 2 | 0.8 |
| 3 | 0.9 |
| 4 | 0.9 |
| 5 | 0.0 |
| 6 | 0.0 |
The average score is 0.58. However, if we analyze the queries within segments, we might discover that we are serving the majority of queries exceptionally well!
Admitting what you’re bad at
Being honest with what you’re bad at is a great way to build trust with your users. If you can accurately identify when something will perform poorly and confidently reject it, then you might be ready to ship a great product while educating your users about the limitations of your application.
It is very important to understand the limitations of your system and to be able to confidently understand the characteristics of your system beyond summary statistics. This is because not all systems are made equal. The behavior of a probabilistic system could be very different from the previous example. Consider the following dataset:
| Query_id | Score |
|---|---|
| 1 | .59 |
| 2 | .58 |
| 3 | .59 |
| 4 | .57 |
A system like this also has the same average score of 0.58, but it’s not as easy to reject any subset of requests…
Consider an RAG application where a large proportion of the queries are regarding timeline queries. If our search engines do not support this time constraint, we will likely be unable to perform well.
| Query_id | Score | Query Type |
|---|---|---|
| 1 | 0.9 | text search |
| 2 | 0.8 | text search |
| 3 | 0.9 | news search |
| 4 | 0.9 | news search |
| 5 | 0.0 | timeline |
| 6 | 0.0 | timeline |
If we’re in a pinch to ship, we could simply build a classification model that detects whether or not these questions are timeline questions and throw a warning. Instead of constantly trying to push the algorithm to do better, we can educate the user and educate them by changing the way that we might design the product.
Detecting segments
Detecting these segments could be accomplished in various ways. We could construct a classifier or employ a language model to categorize them. Additionally, we can utilize clustering algorithms with the embeddings to identify common groups and potentially analyze the mean scores within each group. The sole objective is to identify segments that can enhance our understanding of the activities within specific subgroups.
One of the worst things you can do is to spend months building out a feature that only increases your productivity by a little while ignoring some more important segment of your user base.
By redesigning our application and recognizing its limitations, we can potentially improve performance under certain conditions by identifying the types of tasks we can decline. If we are able to put this segment data into some kind of In-System Observability, we can safely monitor what proportion of questions are being turned down and prioritize our work to maximize coverage.
One of the dangerous things I’ve noticed working with startups is that we often think that the AI works at all… As a result, we want to be able to serve a large general application without much thought into what exactly we want to accomplish.
In my opinion, most of these companies should try to focus on one or two significant areas and identify a good niche to target. If your app is good at one or two tasks, there’s no way you could not find a hundred or two hundred users to test out your application and get feedback quickly. Whereas, if your application is good at nothing, it’s going to be hard to be memorable and provide something that has repeated use. You might get some virality, but very quickly, you’re going to lose the trust of your users and find yourself in a position where you’re trying to reduce churn.
When we’re front-loaded, the ability to use GPT-4 to make predictions, and time to feedback is very important. If we can get feedback quickly, we can iterate quickly. If we can iterate quickly, we can build a better product.
The MVP for an AI application is not as simple as shipping a product with 80% of the features. Instead, it requires a deep understanding of the segments of your users that you can serve well and the ability to educate your users about the segments that you don’t serve well. By understanding the limitations of your system and niching down, you can build a product that is memorable and provides something that has repeated use. This will allow you to get feedback quickly and iterate quickly, ultimately leading to a better product, by identifying your feats of strength.
--- ## The Nockout Story URL: https://subramanya.ai/2024/01/11/the-nockout-story/ Date: 2024-01-11 Tags: Sports, Technology, Community, Innovation
As the co-founders of Nockout, Yash and I, Subramanya, have been on a quest to solve a problem that plagues every sports enthusiast: finding the right place and the right people for playing sports. Our personal struggles with organizing sports activities have led us to create a platform that not only eases these challenges but also promotes a sense of community among sports lovers.
Our frustrations weren’t unique. Across the globe, from tennis courts to basketball hoops, sports enthusiasts were grappling with the same issues: finding the right venue and the right people to play with. This global dilemma was evident in the shared experiences voiced through numerous tweets and conversations among the community.
Bay Club is pretty good. But also trying to find a reliable way to find players is hard (even using PyC).
— Gautam (@gautamtata) January 1, 2024
You should move to New York, where it's even more difficult!https://t.co/c8RjpPzW9x
— Awais Hussain (@Ahussain4) January 1, 2024
someone create an app that shows all public basketball courts and whether or not people are at them or not. this would save a lot of time for me lol.
— thao 🍉 (@holycowitsthao) March 18, 2021
I have wanted pickup hoops forever
— Rob Kornblum (@rkorny) July 5, 2021
These tweets underscore the need for a platform like Nockout.
Nockout is more than just an app; it’s a revolution in the sports community. Designed to be intuitive and user-friendly, it addresses key challenges:
Nockout transcends being a mere application; it’s about building a community bound by the love of sports. It encourages fair play, connects like-minded individuals, and rekindles the joy in sports.
Our vision for Nockout is expansive and all-encompassing:
Be part of a movement that’s reshaping the sports landscape. Sign up for early beta access at Nockout.co, and connect with us on Instagram, LinkedIn, and Twitter. Together, let’s make sports accessible and enjoyable for everyone!
--- ## Enhancing Document Interactions - Leveraging the synergy of Google Cloud Platform, Pinecone, and LLM in Natural Language Communication URL: https://subramanya.ai/2023/06/10/enhancing-document-interactions/ Date: 2023-06-10 Tags: GCP, Pinecone, Large Language Models, OpenAI, Document AI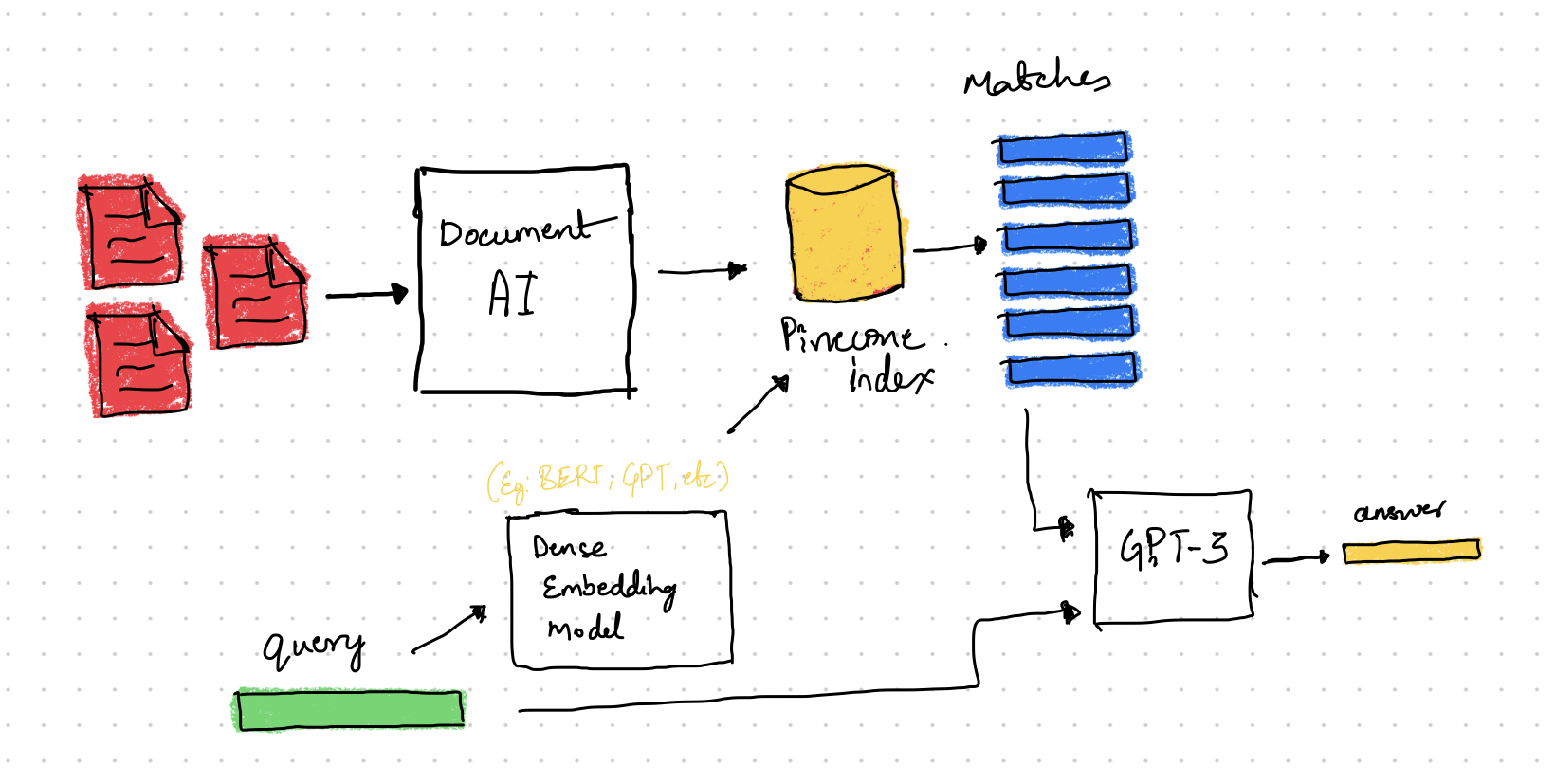 High-level view of system design with Document AI, OpenAI, Pinecone
High-level view of system design with Document AI, OpenAI, Pinecone
In today’s digital era, accessing crucial information from government documents can be overwhelming and time-consuming due to their scanned and non-digitized formats. To address this issue, there is a need for an innovative tool that simplifies navigation, scanning, and digitization of these documents, making them easily readable and searchable. This user-friendly solution will revolutionize the way people interact with government documents, leading to better decision-making, improved public services, and a more informed and engaged citizenry. Developing such a tool is essential for ensuring transparency and accessibility of vital information in the modern world.
To achieve our goal, we will follow a systematic approach consisting of the following steps:
For demonstration of this process, we utilized documents from the Karnataka Resident Data Hub (KRDH) by web scraping.
Demo: Building a powerful question/answering for government documents using Document AI, OpenAI, Pinecone, and Flask
Document AI is a document understanding platform that converts unstructured data from documents into structured data, making it easier to comprehend, analyze, and utilize. To set up Document AI in your Google Cloud Platform (GCP) Console, follow these steps:
pip install --upgrade google-cloud-documentai
After completing these steps, you are ready to use the Document AI API in your code.
def convert_pdf_images_to_text(file_path: str):
"""
Convert PDF or image file containing text into plain text using Google Document AI.
Args:
file_path (str): The file path of the PDF or image file.
Returns:
str: The extracted plain text from the input file.
"""
extention = file_path.split(".")[-1].strip()
if extention == "pdf":
mime_type = "application/pdf"
elif extention == "png":
mime_type = "image/png"
elif extention == "jpg" or extention == "jpeg":
mime_type = "image/jpeg"
opts = ClientOptions(
api_endpoint=f"{location}-documentai.googleapis.com"
)
client = documentai.DocumentProcessorServiceClient(client_options=opts)
# Add the credentials obtained, Project ID, Location and the Processor ID
name = client.processor_path(
project_id, location, processor_id
)
# Read the file into memory
with open(file_path, "rb") as image:
image_content = image.read()
# Load Binary Data into Document AI RawDocument Object
raw_document = documentai.RawDocument(content=image_content, mime_type=mime_type)
# Configure the process request
request = documentai.ProcessRequest(name=name, raw_document=raw_document)
result_document = client.process_document(request=request).document
return result_document.text
In this step, we will use the OpenAI Text Embedding API to generate embeddings that capture the semantic meaning of the extracted text. These embeddings serve as numerical representations of the textual data, allowing us to understand the underlying context and nuances.
After generating the embeddings, we will securely store them in Pinecone, a powerful indexing and similarity search system. By leveraging Pinecone’s efficient storage capabilities, we can effectively organize and index the embeddings for quick and precise retrieval.
With the embeddings stored in Pinecone, our system gains the ability to perform similarity searches. This enables us to find documents that closely match a given query or exhibit similar semantic characteristics.
The following code uses OpenAI’s Text Embedding model to create embeddings for text data. It divides the input text into chunks, generates embeddings for each chunk, and then upserts the embeddings along with associated metadata to a Pinecone search index for efficient searching and retrieval.
def create_embeddings(
text: str, model: str = "text-embedding-ada-002"):
"""
Creates a text embedding using OpenAI's Text Embedding model.
Args:
text (str): The text to embed
model (str, optional): The name of the text embedding model to use.
Defaults to "text-embedding-ada-002".
Returns:
List[float]: The text embedding.
"""
if type(text) == list:
response = openai.Embedding.create(model=model, input=text).data
return [d["embedding"] for d in response]
else:
return [openai.Embedding.create(
model=model, input=[text]).data[0]["embedding"]]∂
def generate_embeddings_upload_to_pinecone(documents: List[Dict[str, Any]]):
"""
Generates text embeddings from the provided documents, then uploads and indexes
them to Pinecone.
Args:
documents (List[Dict[str, Any]]): A list of dictionaries containing
document information.
Each dictionary should include the following keys:
- "Content": The text content of the document.
- "DocumentName": The name of the document.
- "DocumentType": The type/category of the document.
Note:
This function assumes that Pinecone and the associated index have already
been initialized properly. Please make sure to initialize Pinecone first
and set up the index accordingly.
"""
# create chunks
chunks = []
for document in documents:
texts = create_chunks(document["Content"])
chunks.extend(
[
{
"id": str(uuid4()),
"text": texts[i],
"chunk_index": i,
"title": document["DocumentName"],
"type": document["DocumentType"],
}
for i in range(len(texts))
]
)
# initialize Pinecone index, create embeddings, and upsert to Pinecone
index = pinecone.Index("pinecone-index")
for i in tqdm(range(0, len(chunks), 100)):
# find end of batch
i_end = min(len(chunks), i + 100)
batch = chunks[i:i_end]
ids_batch = [x["id"] for x in batch]
texts = [x["text"] for x in batch]
embeds = create_embeddings(text=texts)
# cleanup metadata
meta_batch = [
{
"title": x["title"],
"type": x["type"],
"text": x["text"],
"chunk_index": x["chunk_index"],
}
for x in batch
]
to_upsert = []
for id, embed, meta in list(zip(ids_batch, embeds, meta_batch)):
to_upsert.append(
{
"id": id,
"values": embed,
"metadata": meta,
}
)
# upsert to Pinecone
index.upsert_documents(to_upsert)
For more information on OpenAI’s Text Embedding API, refer to the OpenAI API documentation. For more details on Pinecone, check out the Pinecone documentation.
Finally, with all the necessary components in place, we can witness the powerful functionality of our tool as it matches user queries with relevant context and provides accurate answers.
When a user submits a query, our system leverages the stored embeddings and advanced search capabilities to identify the most relevant documents based on their semantic similarity to the query. By analyzing the contextual information captured in the embeddings, our tool can retrieve the documents that contain the desired information.
def query_and_combine(
self, query_vector: list, top_k: int = 5, threshold: float = 0.75):
"""Query Pinecone index and combine responses to string
Args:
query_embedding (list): Query embedding
index (str): Pinecone index to query
top_k (int, optional): Number of top results to return. Defaults to 5.
threshold : The similarity threshold. Defaults to 0.75
Returns:
str: Combined responses
"""
responses = index.query(query_vector=query_vector, top_k=top_k, metadata=True)
_responses = []
for sample in responses["matches"]:
if sample["score"] < threshold:
continue
if "text" in sample["metadata"]:
_responses.append(sample["metadata"]["text"])
else:
_responses.append(str(sample["metadata"]))
return " \n --- \n ".join(_responses).replace("\n---\n", " \n --- \n ").strip()
def generate_answer(query: str, language: str = "English"):
"""
Generates an answer to a user's query using the context from Pinecone search results
and OpenAI's chat models.
The function takes the user's query, creates a text embedding from it, performs a
Pinecone query to find relevant context, and then generates an answer using OpenAI's
chat models with the given context.
Returns:
A JSON object containing the generated answer.
Note:
This function assumes that Pinecone and the associated index have already been
initialized properly, and that the OpenAI API is set up correctly. Please
make sure to initialize Pinecone and the OpenAI API first.
"""
query_embed = create_embeddings(text=query)[0]
augmented_query = query_and_combine(
query_embed,
top_k=app.config["top_n"],
threshold=app.config["pinecone_threshold"],
)
## Creating the prompt for model
primer = """You are Q&A bot. A highly intelligent system that answers
user questions based on the context provided by the user above
each question. If the information can not be found in the context
provided by the user you truthfully say "I don't know". Be as concise as possible.
"""
augmented_query = augmented_query if augmented_query != "" else "No context found"
text, usage = openai.ChatCompletion.create(
messages=[
{"role": "system", "content": primer},
{
"role": "user",
"content": f"Context: \n {augmented_query} \n --- \n Question: {query} \n Answer in {language}",
},
],
model=app.config["chat_model"],
temperature=app.config["temperature"],
)
return text
The code consists of two functions.
As you reach the end of this blog, we hope you have gained valuable insights into the powerful combination of Google Cloud Platform, Pinecone, and Language Models for revolutionizing document interactions. To dive deeper and explore the code behind this innovative solution, visit our GitHub repository. Feel free to clone, modify, and contribute to the project, and don’t hesitate to share your thoughts and experiences. I would also like to thank Tasheer Hussain B for his contributions. Happy coding!
Searching and finding relevant products is a critical component of an e-commerce website. Providing fast and accurate search results can make the difference between high user satisfaction and user frustration. With recent advancements in natural language understanding and vector search technologies, enhanced search systems have become more accessible and efficient, leading to better user experiences and improved conversion rates.
In this blog post, we’ll explore how to implement a hybrid search system for e-commerce using Pinecone, a high-performance vector search engine, and fine-tuned domain-specific language models. By the end of this post, you’ll not only have a strong understanding of hybrid search but also a practical step-by-step guide to implementing it.
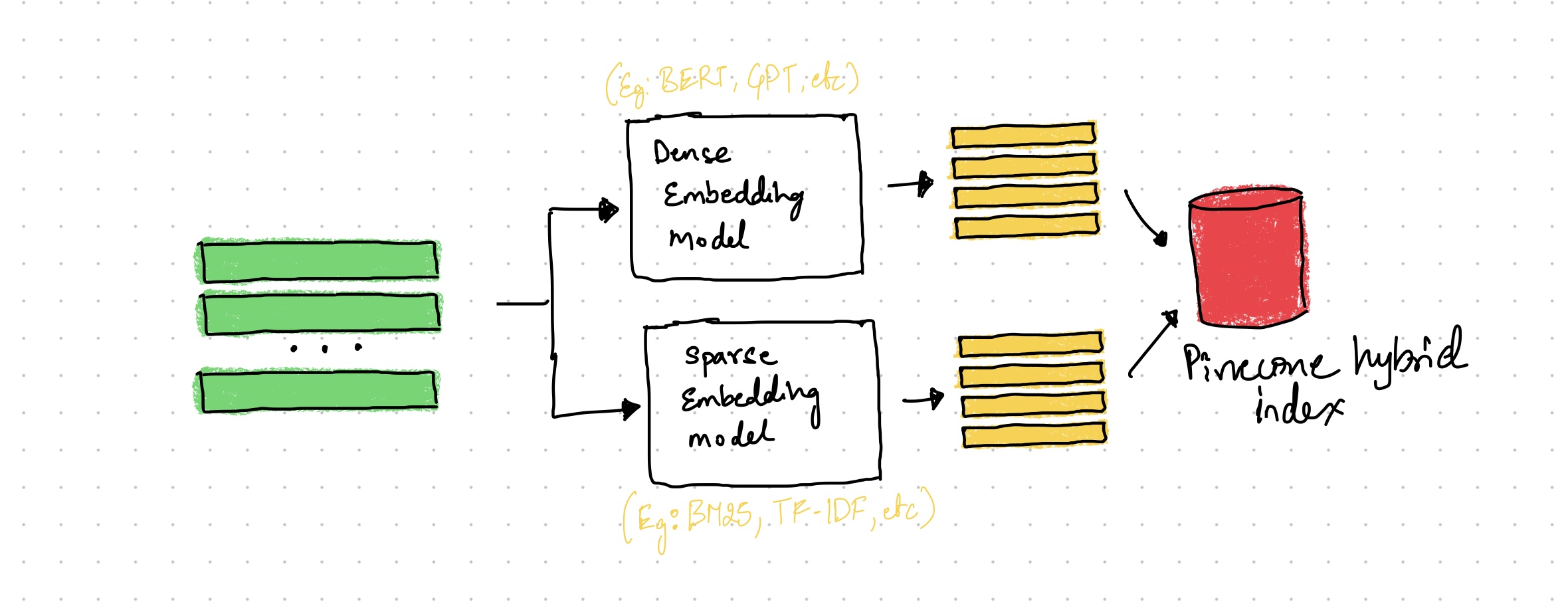 High-level view of simple Pinecone Hybrid Index
High-level view of simple Pinecone Hybrid Index
Before diving into the implementation, let’s quickly understand what hybrid search means. Hybrid search is an approach that combines the strengths of both traditional search (sparse vector search) and vector search (dense vector search) to achieve better search performance across a wide range of domains.
Dense vector search extracts high-quality vector embeddings from text data and performs a similarity search to find relevant documents. However, it often struggles with out-of-domain data when it’s not fine-tuned on domain-specific datasets.
On the other hand, traditional search uses sparse vector representations, like term frequency-inverse document frequency (TF-IDF) or BM25, and does not require any domain-specific fine-tuning. While it can handle new domains, its performance is limited by its inability to understand semantic relations between words and lacks the intelligence of dense retrieval.
Hybrid search tries to mitigate the weaknesses of both approaches by combining them in a single system, leveraging the performance potential of dense vector search and the zero-shot adaptability of traditional search.
Now that we have a basic understanding of hybrid search, let’s dive into its implementation.
We’ll cover the following steps for implementing a hybrid search system:
In recent years, large-scale pre-trained language models like OpenAI’s GPT and Cohere have become increasingly popular for a variety of tasks, including natural language understanding and generation. These models can be fine-tuned on domain-specific data to improve their performance and adapt to specific tasks, such as e-commerce product search.
In our example, we will use a fine-tuned domain-specific language model to generate dense vector embeddings for products and queries. However, you can choose other models or even create your own custom embeddings based on your specific domain.
import torch
from transformers import AutoTokenizer, AutoModel
# Load a pre-trained domain-specific language model
model_name = "your-domain-specific-model"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
# Generate dense vector embeddings for a product description
text = "Nike Air Max sports shoes for men"
inputs = tokenizer(text, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
dense_embedding = outputs.last_hidden_state.mean(dim=1).numpy()
Hybrid search requires both sparse and dense vector representations for our e-commerce data. We’ll now describe how to generate these vectors.
Sparse vector representations, like TF-IDF or BM25, can be created using standard text processing techniques, such as tokenization, stopword removal, and stemming. An example of generating sparse vectors can be achieved using a vocabulary matrix.
# This function generates sparse vector representations of a list of product descriptions
def generate_sparse_vectors(text):
'''Generates sparse vector representations for a list of product descriptions
Args:
text (list): A list of product descriptions
Returns:
sparse_vector (dict): A dictionary of indices and values
'''
sparse_vector = bm25.encode_queries(text)
return sparse_vector
from pinecone_text.sparse import BM25Encoder
# Create the BM25 encoder and fit the data
bm25 = BM25Encoder()
bm25.fit(new_df.full_data)
# Create the sparse vectors
sparse_vectors = []
for product_description in product_descriptions:
sparse_vectors.append(generate_sparse_vectors(text=product_description))
Dense vector representations can be generated using pre-trained or custom domain-specific language models. In our previous example, we used a domain-specific language model to generate dense vector embeddings for a product description.
def generate_dense_vector(text):
'''Generates dense vector embeddings for a list of product descriptions
Args:
text (list): A list of product descriptions
Returns:
dense_embedding (np.array): A numpy array of dense vector embeddings
'''
# Tokenize the text and convert to PyTorch tensors
inputs = tokenizer(text, return_tensors="pt")
# Generate the embeddings with the pre-trained model
with torch.no_grad():
outputs = model(**inputs)
dense_vector = outputs.last_hidden_state.mean(dim=1).numpy()
return dense_vector
# Generate dense vector embeddings for a list of product descriptions
dense_vectors = []
for product_description in product_descriptions:
dense_vectors.append(generate_dense_vector(text=product_description))
Pinecone is a high-performance vector search engine that supports hybrid search. It enables the creation of a single index for both sparse and dense vectors and seamlessly handles search queries across different data modalities.
To use Pinecone, you’ll need to sign up for an account, install the Pinecone client, and set up your API key and environment.
# Create a Pinecone hybrid search index
import pinecone
pinecone.init(
api_key="YOUR_API_KEY", # app.pinecone.io
environment="YOUR_ENV" # find next to api key in console
)
# Create a Pinecone hybrid search index
index_name = "ecommerce-hybrid-search"
pinecone.create_index(
index_name = index_name,
dimension = MODEL_DIMENSION, # dimensionality of dense model
metric = "dotproduct"
)
# connect to the index
index = pinecone.Index(index_name=index_name)
# view index stats
index.describe_index_stats()
With our sparse and dense vectors generated and Pinecone set up, we can now build a hybrid search pipeline. This pipeline includes the following steps:
def add_product_data_to_index(product_ids, sparse_vectors, dense_vectors, metadata=None):
"""Upserts product data to the Pinecone index.
Args:
product_ids (`list` of `str`): Product IDs.
sparse_vectors (`list` of `list` of `float`): Sparse vectors.
dense_vectors (`list` of `list` of `float`): Dense vectors.
metadata (`list` of `list` of `str`): Optional metadata.
Returns:
None
"""
batch_size = 32
# Loop through the product IDs in batches.
for i in range(0, len(product_ids), batch_size):
i_end = min(i + batch_size, len(product_ids))
ids = product_ids[i:i_end]
sparse_batch = sparse_vectors[i:i_end]
dense_batch = dense_vectors[i:i_end]
meta_batch = metadata[i:i_end] if metadata else []
vectors = []
for _id, sparse, dense, meta in zip(ids, sparse_batch, dense_batch, meta_batch):
vectors.append({
'id': _id,
'sparse_values': sparse,
'values': dense,
'metadata': meta
})
# Upsert the vectors into the Pinecone index.
index.upsert(vectors=vectors)
add_product_data_to_index(product_ids, sparse_vectors, dense_vectors)
Now that our data is indexed, we can perform hybrid search queries.
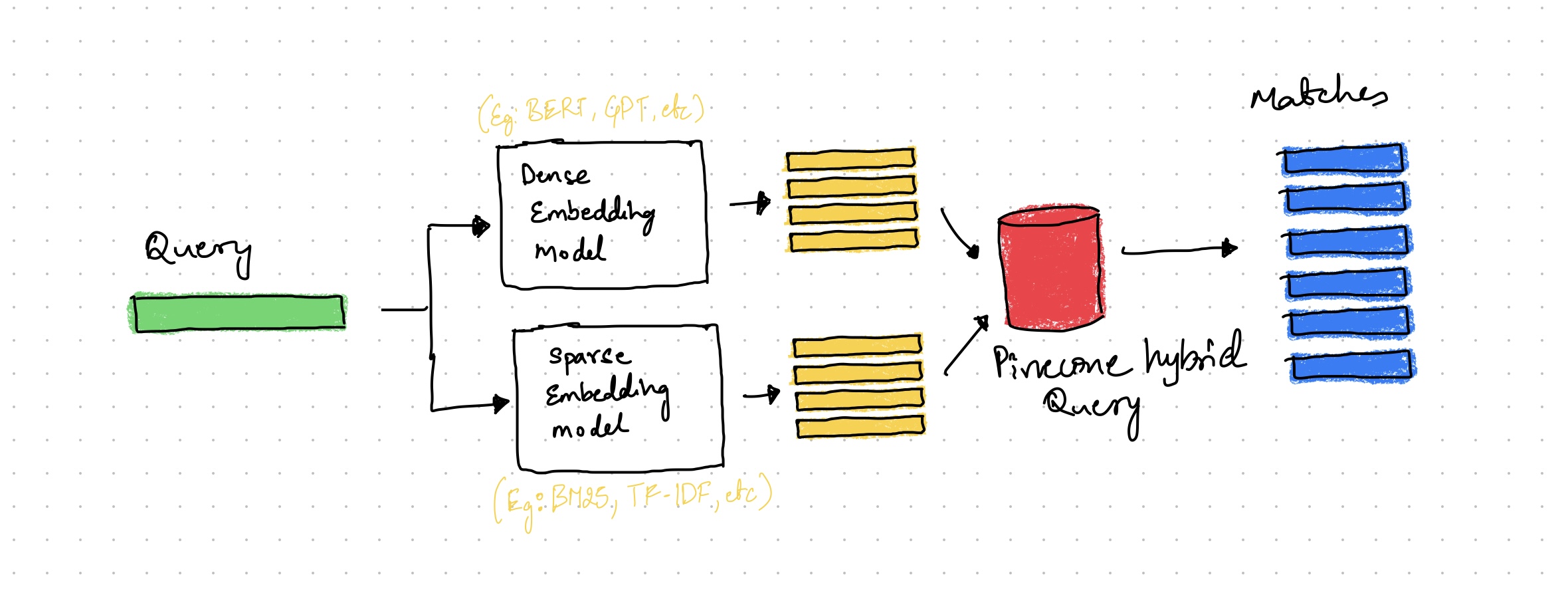 High-level view of simple Pinecone Hybrid Query
High-level view of simple Pinecone Hybrid Query
To make hybrid search queries, we’ll create a function that takes a query, the number of top results, and an alpha parameter to control the weighting between dense and sparse vector search scores.
def hybrid_scale(dense, sparse, alpha: float):
"""Hybrid vector scaling using a convex combination
alpha * dense + (1 - alpha) * sparse
Args:
dense: Array of floats representing
sparse: a dict of `indices` and `values`
alpha: float between 0 and 1 where 0 == sparse only
and 1 == dense only
"""
if alpha < 0 or alpha > 1:
raise ValueError("Alpha must be between 0 and 1")
# scale sparse and dense vectors to create hybrid search vecs
hsparse = {
'indices': sparse['indices'],
'values': [v * (1 - alpha) for v in sparse['values']]
}
hdense = [v * alpha for v in dense]
return hdense, hsparse
def search_products(query, top_k=10, alpha=0.5):
# Generate sparse query vector
sparse_query_vector = generate_sparse_vector(query)
# Generate dense query vector
dense_query_vector = generate_dense_vector(query)
# Calculate hybrid query vector
dense_query_vector, sparse_query_vector = hybrid_scale(dense_query_vector, sparse_query_vector, alpha)
# Search products using Pinecone
results = index.query(
vector=dense_query_vector,
sparse_vector=sparse_query_vector,
top_k=top_k
)
return results
We can then use this function to search for relevant products in our e-commerce dataset.
query = "running shoes for women"
results = search_products(query, top_k=5)
for result in results:
print(result['id'], result['metadata']['product_name'], result['score'])
Experimenting with different values for the alpha parameter will help you find the optimal balance between sparse and dense vector search for your specific domain.
In this blog post, we demonstrated how to build a hybrid search system for e-commerce using Pinecone and domain-specific language models. Hybrid search enables us to combine the strengths of both traditional search and vector search, improving search performance and adaptability across diverse domains.
By following the steps and code snippets provided in this post, you can implement your own hybrid search system tailored to your e-commerce website’s specific requirements. Start exploring Pinecone and improve your e-commerce search experience today!
In my previous blog posts, we covered the basics of using the shell, introduced shell scripting for beginners, and explored advanced techniques and best practices. In this blog post, we will focus on working with files and directories in shell scripts. We will discuss common tasks such as creating, copying, moving, and deleting files and directories, as well as reading and writing to files. We will also provide some resources for further learning.
To create a new file in a shell script, you can use the touch command:
touch new_file.txt
To create a new directory, you can use the mkdir command:
mkdir new_directory
To copy a file, you can use the cp command:
cp source_file.txt destination_file.txt
To copy a directory, you can use the -r (recursive) option:
cp -r source_directory destination_directory
To move a file or directory, you can use the mv command:
mv source_file.txt destination_file.txt
To delete a file, you can use the rm command:
rm file_to_delete.txt
To delete a directory, you can use the -r (recursive) option:
rm -r directory_to_delete
To read the contents of a file, you can use the cat command:
cat file_to_read.txt
To write to a file, you can use the > operator to overwrite the file or the >> operator to append to the file:
echo "This is a new line" > file_to_write.txt
echo "This is another new line" >> file_to_write.txt
To read a file line by line, you can use a while loop with the read command:
#!/bin/bash
while IFS= read -r line; do
echo "Line: $line"
done < file_to_read.txt
To search for files and directories, you can use the find command:
find /path/to/search -name "file_pattern"
For example, to find all .txt files in the /home/user directory, you can use:
find /home/user -name "*.txt"
To further improve your skills in working with files and directories in shell scripts, here are some resources:
find command in Linux.In conclusion, working with files and directories is an essential aspect of shell scripting. By mastering common tasks such as creating, copying, moving, and deleting files and directories, as well as reading and writing to files, you will be well-equipped to handle a wide range of shell scripting tasks.
--- ## Demystifying the Shell Scripting: Advanced Techniques and Best Practices URL: https://subramanya.ai/2022/12/28/demystifying-the-shell-scripting-advanced-techniques-and-best-practices/ Date: 2022-12-28 Tags: Shell Scripting, Bash, Shell, Error Handling, Command Substitution, Process Management, Best PracticesIn my previous blog posts, we covered the basics of using the shell and introduced shell scripting for beginners. Now that you have a solid foundation in shell scripting, it’s time to explore some advanced techniques and best practices that will help you write more efficient, robust, and maintainable scripts. In this blog post, we will discuss error handling, command substitution, process management, and best practices for writing shell scripts. We will also provide some resources for further learning.
Error handling is an essential aspect of writing robust shell scripts. By default, shell scripts continue to execute subsequent commands even if an error occurs. To change this behavior and make your script exit immediately if a command fails, you can use the set -e option:
#!/bin/bash
set -e
# Your script here
You can also use the trap command to define custom error handling behavior. For example, you can create a cleanup function that will be called if your script exits unexpectedly:
#!/bin/bash
function cleanup() {
echo "Cleaning up before exiting..."
# Your cleanup code here
}
trap cleanup EXIT
# Your script here
Command substitution allows you to capture the output of a command and store it in a variable. This can be useful for processing the output of a command within your script. There are two ways to perform command substitution:
output=`ls`
$():output=$(ls)
The $() syntax is preferred because it is more readable and can be easily nested.
Shell scripts often need to manage background processes, such as starting, stopping, or monitoring them. Here are some useful commands for process management:
&: Run a command in the background by appending an ampersand (&) to the command.long_running_command &
wait: Wait for a background process to complete before continuing with the script.long_running_command &
wait
kill: Terminate a process by sending a signal to it.kill -9 process_id
ps: List running processes and their process IDs.ps aux
Here are some best practices for writing shell scripts:
local keyword to limit the scope of variables within functions.[[ ]] syntax for conditional expressions, as it is more robust than [ ].To further improve your shell scripting skills, here are some resources:
In conclusion, mastering advanced techniques and best practices in shell scripting will help you write more efficient, robust, and maintainable scripts. By understanding error handling, command substitution, process management, and following best practices, you will be well on your way to becoming a shell scripting expert.
--- ## Demystifying the Shell Scripting: A Beginner's Guide URL: https://subramanya.ai/2022/12/28/demystifying-the-shell-scripting-a-beginners-guide/ Date: 2022-12-28 Tags: Shell Scripting, Bash, ShellIn my previous blog post, we introduced the basics of using the shell, navigating within it, connecting programs, and some miscellaneous tips and tricks. Now that you have a good understanding of the shell, it’s time to take your skills to the next level by learning shell scripting. Shell scripting allows you to automate tasks, perform complex operations, and create custom commands. In this blog post, we will explore the basics of shell scripting, including variables, control structures, loops, and functions. We will also provide some resources for further learning.
Shell scripting is the process of writing a series of commands in a text file (called a script) that can be executed by the shell. These scripts can be used to automate repetitive tasks, perform complex operations, and create custom commands. Shell scripts are typically written in the same language as the shell itself (e.g., Bash, Zsh, or Fish).
To create a shell script, simply create a new text file with the extension .sh (e.g., myscript.sh). The first line of the script should be a “shebang” (#!) followed by the path to the shell interpreter (e.g., #!/bin/bash for Bash scripts). This line tells the operating system which interpreter to use when executing the script.
Here’s an example of a simple shell script that prints “Hello, World!” to the console:
#!/bin/bash
echo "Hello, World!"
To execute the script, you need to make it executable by changing its permissions using the chmod command:
chmod +x myscript.sh
Now you can run the script by typing ./myscript.sh in the terminal.
Variables in shell scripts are used to store values that can be referenced and manipulated throughout the script. To create a variable, use the = operator without any spaces:
my_variable="Hello, World!"
To reference the value of a variable, use the $ symbol:
echo $my_variable
Control structures, such as if statements and case statements, allow you to add conditional logic to your shell scripts. Here’s an example of an if statement:
#!/bin/bash
number=5
if [ $number -gt 3 ]; then
echo "The number is greater than 3."
else
echo "The number is not greater than 3."
fi
In this example, the script checks if the value of the number variable is greater than 3 and prints a message accordingly.
Loops allow you to execute a block of code multiple times. There are two main types of loops in shell scripting: for loops and while loops. Here’s an example of a for loop:
#!/bin/bash
for i in {1..5}; do
echo "Iteration $i"
done
This script will print the message “Iteration X” five times, with X being the current iteration number.
Functions are reusable blocks of code that can be called with a specific set of arguments. To create a function, use the function keyword followed by the function name and a pair of parentheses:
#!/bin/bash
function greet() {
echo "Hello, $1!"
}
greet "World"
In this example, the greet function takes one argument ($1) and prints a greeting message using that argument.
To further improve your shell scripting skills, here are some resources:
In conclusion, shell scripting is a powerful tool that allows you to automate tasks, perform complex operations, and create custom commands. By understanding the basics of shell scripting, including variables, control structures, loops, and functions, you will be well on your way to becoming a shell scripting expert.
--- ## Demystifying the Shell: A Beginner's Guide URL: https://subramanya.ai/2022/12/28/demystifying-the-shell-a-beginners-guide/ Date: 2022-12-28 Tags: Bash, ShellThe shell is an essential tool for any developer, system administrator, or even a casual computer user. It allows you to interact with your computer’s operating system using text-based commands, giving you more control and flexibility than graphical user interfaces (GUIs). In this blog post, we will explore the basics of using the shell, navigating within it, connecting programs, and some miscellaneous tips and tricks. We will also provide some resources for further learning.
The shell is a command-line interface (CLI) that allows you to interact with your computer’s operating system by typing commands. It is a program that takes your commands, interprets them, and then sends them to the operating system to be executed. There are various types of shells available, such as Bash (Bourne Again SHell), Zsh (Z Shell), and Fish (Friendly Interactive SHell), each with its own unique features and capabilities.
To start using the shell, you need to open a terminal emulator. On Linux and macOS, you can usually find the terminal application in your Applications or Utilities folder. On Windows, you can use the Command Prompt, PowerShell, or install a third-party terminal emulator like Git Bash or Windows Subsystem for Linux (WSL).
Once you have opened the terminal, you can start typing commands. For example, to list the files and directories in your current directory, you can type the following command:
ls
This command will display the contents of your current directory. You can also use flags (options) to modify the behavior of a command. For example, to display the contents of a directory in a more detailed format, you can use the -l flag:
ls -l
Navigating within the shell is quite simple. You can use the cd (change directory) command to move between directories. For example, to move to the /home/user/Documents directory, you can type:
cd /home/user/Documents
To move up one directory level, you can use the .. notation:
cd ..
You can also use the pwd (print working directory) command to display the current directory you are in:
pwd
In the shell, you can connect multiple programs together using pipes (|). This allows you to pass the output of one program as input to another program. For example, you can use the grep command to search for a specific word in a file, and then use the wc (word count) command to count the number of lines containing that word:
grep 'search_word' file.txt | wc -l
This command will first search for the word ‘search_word’ in the file ‘file.txt’ and then count the number of lines containing that word.
Here are some miscellaneous tips and tricks for using the shell:
history command to view your command history.clear command to clear the terminal screen.man command followed by a command name to view the manual page for that command (e.g., man ls).TAB key to auto-complete file and directory names.CTRL + C keyboard shortcut to cancel a running command.To further improve your shell skills, here are some resources:
In conclusion, mastering the shell is an essential skill for any computer user. It allows you to interact with your computer’s operating system more efficiently and effectively than using graphical user interfaces. By understanding the basics of using the shell, navigating within it, connecting programs, and learning some miscellaneous tips and tricks, you will be well on your way to becoming a shell expert.
--- ## Version Control (Git) URL: https://subramanya.ai/2022/12/21/version-control/ Date: 2022-12-21 Tags: Git, Version ControlVersion control systems (VCSs) are tools used to track changes to source code (or other collections of files and folders). As the name implies, these tools help maintain a history of changes; furthermore, they facilitate collaboration. VCSs track changes to a folder and its contents in a series of snapshots, where each snapshot encapsulates the entire state of files/folders within a top-level directory. VCSs also maintain metadata like who created each snapshot, messages associated with each snapshot, and so on.
Why is version control useful? Even when you’re working by yourself, it can let you look at old snapshots of a project, keep a log of why certain changes were made, work on parallel branches of development, and much more. When working with others, it’s an invaluable tool for seeing what other people have changed, as well as resolving conflicts in concurrent development.
Modern VCSs also let you easily (and often automatically) answer questions like:
While other VCSs exist, Git is the de facto standard for version control. This XKCD comic captures Git’s reputation:

Because Git’s interface is a leaky abstraction, learning Git top-down (starting with its interface / command-line interface) can lead to a lot of confusion. It’s possible to memorize a handful of commands and think of them as magic incantations, and follow the approach in the comic above whenever anything goes wrong.
While Git admittedly has an ugly interface, its underlying design and ideas are beautiful. While an ugly interface has to be memorized, a beautiful design can be understood. For this reason, we give a bottom-up explanation of Git, starting with its data model and later covering the command-line interface. Once the data model is understood, the commands can be better understood in terms of how they manipulate the underlying data model.
There are many ad-hoc approaches you could take to version control. Git has a well-thought-out model that enables all the nice features of version control, like maintaining history, supporting branches, and enabling collaboration.
Git models the history of a collection of files and folders within some top-level directory as a series of snapshots. In Git terminology, a file is called a “blob”, and it’s just a bunch of bytes. A directory is called a “tree”, and it maps names to blobs or trees (so directories can contain other directories). A snapshot is the top-level tree that is being tracked. For example, we might have a tree as follows:
<root> (tree)
|
+- foo (tree)
| |
| + bar.txt (blob, contents = "hello world")
|
+- baz.txt (blob, contents = "git is wonderful")
The top-level tree contains two elements, a tree “foo” (that itself contains one element, a blob “bar.txt”), and a blob “baz.txt”.
How should a version control system relate snapshots? One simple model would be to have a linear history. A history would be a list of snapshots in time-order. For many reasons, Git doesn’t use a simple model like this.
In Git, a history is a directed acyclic graph (DAG) of snapshots. That may sound like a fancy math word, but don’t be intimidated. All this means is that each snapshot in Git refers to a set of “parents”, the snapshots that preceded it. It’s a set of parents rather than a single parent (as would be the case in a linear history) because a snapshot might descend from multiple parents, for example, due to combining (merging) two parallel branches of development.
Git calls these snapshots “commit”s. Visualizing a commit history might look something like this:
o <-- o <-- o <-- o
^
\
--- o <-- o
In the ASCII art above, the os correspond to individual commits (snapshots). The arrows point to the parent of each commit (it’s a “comes before” relation, not “comes after”). After the third commit, the history branches into two separate branches. This might correspond to, for example, two separate features being developed in parallel, independently from each other. In the future, these branches may be merged to create a new snapshot that incorporates both of the features, producing a new history that looks like this, with the newly created merge commit shown in bold:
o <-- o <-- o <-- o <---- o
^ /
\ v
--- o <-- o
Commits in Git are immutable. This doesn’t mean that mistakes can’t be corrected, however; it’s just that “edits” to the commit history are actually creating entirely new commits, and references (see below) are updated to point to the new ones.
It may be instructive to see Git’s data model written down in pseudocode:
// a file is a bunch of bytes
type blob = array<byte>
// a directory contains named files and directories
type tree = map<string, tree | blob>
// a commit has parents, metadata, and the top-level tree
type commit = struct {
parents: array<commit>
author: string
message: string
snapshot: tree
}
It’s a clean, simple model of history.
An “object” is a blob, tree, or commit:
type object = blob | tree | commit
In Git data store, all objects are content-addressed by their SHA-1 hash.
objects = map<string, object>
def store(object):
id = sha1(object)
objects[id] = object
def load(id):
return objects[id]
Blobs, trees, and commits are unified in this way: they are all objects. When they reference other objects, they don’t actually contain them in their on-disk representation, but have a reference to them by their hash.
For example, the tree for the example directory structure above
(visualized using git cat-file -p 698281bc680d1995c5f4caaf3359721a5a58d48d),
looks like this:
100644 blob 4448adbf7ecd394f42ae135bbeed9676e894af85 baz.txt
040000 tree c68d233a33c5c06e0340e4c224f0afca87c8ce87 foo
The tree itself contains pointers to its contents, baz.txt (a blob) and foo
(a tree). If we look at the contents addressed by the hash corresponding to
baz.txt with git cat-file -p 4448adbf7ecd394f42ae135bbeed9676e894af85, we get
the following:
git is wonderful
Now, all snapshots can be identified by their SHA-1 hashes. That’s inconvenient, because humans aren’t good at remembering strings of 40 hexadecimal characters.
Git’s solution to this problem is human-readable names for SHA-1 hashes, called “references”. References are pointers to commits. Unlike objects, which are
immutable, references are mutable (can be updated to point to a new commit). For example, the master reference usually points to the latest commit in the
main branch of development.
references = map<string, string>
def update_reference(name, id):
references[name] = id
def read_reference(name):
return references[name]
def load_reference(name_or_id):
if name_or_id in references:
return load(references[name_or_id])
else:
return load(name_or_id)
With this, Git can use human-readable names like “master” to refer to a particular snapshot in the history, instead of a long hexadecimal string.
One detail is that we often want a notion of “where we currently are” in the history, so that when we take a new snapshot, we know what it is relative to (how we set the parents field of the commit). In Git, that “where we currently are” is a special reference called “HEAD”.
Finally, we can define what (roughly) is a Git repository: it is the data objects and references.
On disk, all Git stores are objects and references: that’s all there is to Git’s data model. All git commands map to some manipulation of the commit DAG by
adding objects and adding/updating references.
Whenever you’re typing in any command, think about what manipulation the command is making to the underlying graph data structure. Conversely, if you’re trying to make a particular kind of change to the commit DAG, e.g. “discard uncommitted changes and make the ‘master’ ref point to commit 5d83f9e”, there’s probably a command to do it (e.g. in this case, git checkout master; git reset --hard 5d83f9e).
This is another concept that’s orthogonal to the data model, but it’s a part of the interface to create commits.
One way you might imagine implementing snapshotting as described above is to have a “create snapshot” command that creates a new snapshot based on the current state of the working directory. Some version control tools work like this, but not Git. We want clean snapshots, and it might not always be ideal to make a snapshot from the current state. For example, imagine a scenario where you’ve implemented two separate features, and you want to create two separate commits, where the first introduces the first feature, and the next introduces the second feature. Or imagine a scenario where you have debugging print statements added all over your code, along with a bugfix; you want to commit the bugfix while discarding all the print statements.
Git accommodates such scenarios by allowing you to specify which modifications should be included in the next snapshot through a mechanism called the “staging area”.
To avoid duplicating information, we’re not going to explain the commands below in detail. See the highly recommended Pro Git for more information.
The git init command initializes a new Git repository, with repository metadata being stored in the .git directory:
$ mkdir myproject
$ cd myproject
$ git init
Initialized empty Git repository in .git
$ git status
On branch master
No commits yet
nothing to commit (create/copy files and use "git add" to track)
How do we interpret this output? “No commits yet” basically means our version history is empty. Let’s fix that.
$ echo "hello, git" > hello.txt
$ git add hello.txt
$ git status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: hello.txt
$ git commit -m 'Initial commit'
[master (root-commit) 4515d17] Initial commit
1 file changed, 1 insertion(+)
create mode 100644 hello.txt
With this, we’ve git added a file to the staging area, and then git commited that change, adding a simple commit message “Initial commit”. If we didn’t specify a -m option, Git would open our text editor to allow us type a commit message.
Now that we have a non-empty version history, we can visualize the history. Visualizing the history as a DAG can be especially helpful in understanding the current status of the repo and connecting it with your understanding of the Git data model.
The git log command visualizes history. By default, it shows a flattened version, which hides the graph structure. If you use a command like git log --all --graph --decorate, it will show you the full version history of the repository, visualized in graph form.
$ git log --all --graph --decorate
* commit 4515d17a167bdef0a91ee7d50d75b12c9c2652aa (HEAD -> master)
Author: Subramanya N <subramanyanagabhushan@gmail.com>
Date: Tue Dec 21 22:18:36 2020 -0500
Initial commit
This doesn’t look all that graph-like, because it only contains a single node. Let’s make some more changes, author a new commit, and visualize the history once more.
$ echo "another line" >> hello.txt
$ git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: hello.txt
no changes added to commit (use "git add" and/or "git commit -a")
$ git add hello.txt
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: hello.txt
$ git commit -m 'Add a line'
[master 35f60a8] Add a line
1 file changed, 1 insertion(+)
Now, if we visualize the history again, we’ll see some of the graph structure:
* commit 35f60a825be0106036dd2fbc7657598eb7b04c67 (HEAD -> master)
| Author: Subramanya N <subramanyanagabhushan@gmail.com>
| Date: Tue Dec 21 22:26:20 2020 -0500
| Add a line
* commit 4515d17a167bdef0a91ee7d50d75b12c9c2652aa
Author: Subramanya N <subramanyanagabhushan@gmail.com>
Date: Tue Dec 21 22:18:36 2020 -0500
Initial commit
Also, note that it shows the current HEAD, along with the current branch (master).
We can look at old versions using the git checkout command.
$ git checkout 4515d17 # previous commit hash; yours will be different
Note: checking out '4515d17'.
You are in 'detached HEAD' state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by performing another checkout.
If you want to create a new branch to retain commits you create, you may
do so (now or later) by using -b with the checkout command again. Example:
git checkout -b <new-branch-name>
HEAD is now at 4515d17 Initial commit
$ cat hello.txt
hello, git
$ git checkout master
Previous HEAD position was 4515d17 Initial commit
Switched to branch 'master'
$ cat hello.txt
hello, git
another line
Git can show you how files have evolved (differences, or diffs) using the git
diff command:
$ git diff 4515d17 hello.txt
diff --git c/hello.txt w/hello.txt
index 94bab17..f0013b2 100644
--- c/hello.txt
+++ w/hello.txt
@@ -1 +1,2 @@
hello, git
+another line
git help <command>: get help for a git commandgit init: creates a new git repo, with data stored in the .git directorygit status: tells you what’s going ongit add <filename>: adds files to staging areagit commit: creates a new commit
git log: shows a flattened log of historygit log --all --graph --decorate: visualizes history as a DAGgit diff <filename>: show changes you made relative to the staging areagit diff <revision> <filename>: shows differences in a file between snapshotsgit checkout <revision>: updates HEAD and current branchBranching allows you to “fork” version history. It can be helpful for working on independent features or bug fixes in parallel. The git branch command can be used to create new branches; git checkout -b <branch name> creates and branch and checks it out.
Merging is the opposite of branching: it allows you to combine forked version histories, e.g. merging a feature branch back into master. The git merge command is used for merging.
git branch: shows branchesgit branch <name>: creates a branchgit checkout -b <name>: creates a branch and switches to it
git branch <name>; git checkout <name>git merge <revision>: merges into current branchgit mergetool: use a fancy tool to help resolve merge conflictsgit rebase: rebase set of patches onto a new basegit remote: list remotesgit remote add <name> <url>: add a remotegit push <remote> <local branch>:<remote branch>: send objects to remote, and update remote referencegit branch --set-upstream-to=<remote>/<remote branch>: set up correspondence between local and remote branchgit fetch: retrieve objects/references from a remotegit pull: same as git fetch; git mergegit clone: download repository from remotegit commit --amend: edit a commit’s contents/messagegit reset HEAD <file>: unstage a filegit checkout -- <file>: discard changesgit config: Git is highly customizablegit clone --depth=1: shallow clone, without entire version historygit add -p: interactive staginggit rebase -i: interactive rebasinggit blame: show who last edited which linegit stash: temporarily remove modifications to working directorygit bisect: binary search history (e.g. for regressions).gitignore: specify intentionally untracked files to ignore